Inter-VM Cache Affinity
В ситуации, когда две ВМ на одном и том же хосте интенсивно обмениваются информацией, возможно увеличение производительности при работе в пределах одного кэша. Эта ситуация применима только к разделению кэша между ВМ, консолидация vSMP применяется для консолидации кэша внутри одной машины. Как следствие, vSMP работает только для многопроцессорных машин, а в данном случае возможно консолидировать и однопроцессорные машины. Планировщик ESX в автоматическом режиме определяет "разговорчивые" машины на хосте и пытается разместить их в пределах LLC. Тем не менее, этого может и не случиться, в зависимости от нагрузки на хост.
Aggressive Hyperthreading Support
Балансировка нагрузки для архитектуры с многопоточными процессорами (hyperthreading) - тема для отдельного поста. Политика миграции по умолчанию выбирает полностью незагруженное ядро (оба потока свободны), предпочитая его частично загруженному - тому, у которого загружен один поток. Посколько оба аппаратных потока конкурируют за один процессор, использование частично загруженного ядра приводит к ухудшению производительности, по сравнению с полностью свободным ядром. Как результат, наблюдается асимметрия в вычислительной мощности среди pCPU, в зависимости от того, насколько загружен поток-близнец. Эта асимметрия ухудшает "справедливость распределения" (fairness). Например, один vCPU работает на частично загруженном ядре, а другой на полностью свободном. Если оба vCPU идентичны по требованиям к вычислительной мощности, то получается несправедливая ситуация, и от нее надо уходить.
В связи с этой асимметрией планировщик рассчитывает потребление процессорной мощности в меньшем объеме для vCPU, расположенном на частично загруженном ядре. В случае если vCPU исполнялся на частично загруженном ядре на протяжении длительного времени, то планировщик может перенести данный vCPU на полностью свободное ядро с целью компенсации недополученной процессорной мощности. В противном случае данный vCPU может оказаться в ситуации постоянного отставания от других vCPU, работающих на полностью свободных ядрах. Компенсация выражается в том, что второй аппаратный поток ядра намеренно сохраняется незагруженным. В этом случае может быть неполной утилизация аппаратных потоков, однако общее снижение производительности достаточно незначительно, ввиду ограниченности потенциального прироста производительности из-за многопоточности.
Внутреннее тестирование показывает, что последние поколения многопоточных процессоров демонстрируют больший прирост производительности и меньшее влияение загрузки потока-близнеца. Это наблюдение дает повод для более агрессивного использования частично загруженных ядер для балансировки нагрузки - полностью свободные ядра все еще предпочтительнее, но если нет полностью свободных, то частично загруженное ядро имеет больше шансов. Ранее частично загруженные ядро могло быть вовсе не выбранным для гарантии справедливого распределения процессорного времени. Эксперименты показывают, что агрессивное использование многопоточности улучшает утилизацию процессора и увеличивает производительность приложений без значительного влияния на справедливость распределения.
Стоит заметить, что бухгалтерия планировщика слегка изменилась - загрузка процессора считается со скидкой, если поток-близнец загружен. Это приводит к ситуации, в которой общая загрузка системы считается меньше реальной. Например, возьмем ситуацию, в которой оба потока-близнеца постоянно загружены. В терминах утилизации процессора система полностью загружена, но в терминах бухгалтерии процесса время исполнения, которое будет списываться со счета исполняемых vCPU, меньше полной загрузки ввиду скидки. В esxtop для поддержки этого появился новый счетчик “PCPU Util” для отображения утилизации системы, а “PCPU Used” все еще показывает текущее время исполнения. Подробности - man esxtop.
Extended Fairness Support
Базовые алгоритмы планировщика гарантируют справедливое распределение ресурсов процессора между виртуальными машиными согласно их конфигурации. В некоторых случаях справедливое распредление процессорных ресурсов может не вести напрямую к метрикам приложений, ввиду комплексности архитектуры и завимости производительности от, например, кэша на кристалле и ширине шины памяти.
Для расширения понятия справедливого распределения ресурсов, миграции могут случаться, например, для справедливого распределения кэша на кристале или ширины полосы доступа к памяти. Однако, в силу стоимости самой миграции, происходит это не так часто, обычно раз в несколько секунда, чтобы снизить негативное влияние на общую производительности.
Прим: поддержка расширенного справедливого распределения ресурсов также реализована в алгоритмах балансировки для NUMA.
Продолжение следует.
Оригинал: "VMware® vSphere™: The CPU Scheduler in VMware ESX® 4.1"
четверг, 29 декабря 2011 г.
понедельник, 26 декабря 2011 г.
ESX CPU scheduler deepdive. Multicore-Aware Load Balancing. Part 1.
Архитектура CMP (chip mutiprocessor) привносит новые проблемы алгоритмам балансировки нагрузки ввиду различных вариантов исполнения кэша на чипе. Предыдущие поколения процессоров обычно были с частным L2 кэшем, а более новые имеют общий как L3, так и L2 кэш. Также, количество ядер, использующих общий кэш варьируется от двух до четырех и более. Кэш последнего уровня (LLC - last level cache) - кэш, после которого идет обращение к оперативной памяти. Поскольку задержка при доступе к LLC и RAM различается как минимум на порядок, поддержание высокого уровня cache-hit для LLC становится жизненно необходимым для высокой производительности.
Балансировка нагрузки достигается миграцией vCPU, но после миграции vCPU должен "разогреть" кэш. И в связи с этим реальная стоимость миграции очень сильно зависит от того, требует ли разогрев кэша доступа к оперативной памяти, который не может быть удовлетворен за счет LLC. Иными словами, миграция в пределах LLC значительно дешевле, чем между LLC. Ранее эта внутричиповая топология игнорировалась планировщиком и стоимость миграции считалась одинаковой и фиксированной. Тем не менее, результат был удовлетворительным, поскольку механизм приоритезации миграции между ячейками планировщика (scheduler cell) приводил к высокому уровню между-LLC миграций - ячейка в большинстве случаев равняется одному, как максимум двум LLC.
В ESX4 понятие ячейки планировщика более не используется, а следовательно между-LLC миграции более не приоритезируются. Таким образом механизм балансировки нагрузки занчительно улучшился, поскольку миграция внутри LLC предпочтительнее миграции между LLC. Когда планировщик выбирает pCPU для миграции, локальный процессор, разделяющий LLC, всегда предпочтительнее удаленного, не разделяющего тот же LLC. Тем не менее, миграция на удаленный pCPU все еще возможна, если выбор локального pCPU не может решить проблему балансировки нагрузки.
CPU Load-Based Migration Throttling
В ESX4 vCPU, привносящий значительную нагрузку на текущий pCPU не будет мигрировать, вместо этого планировщик будет в первую очередь мигрировать vCPU с низкой нагрузкой. Данный механизм позволяет снизить количество миграций из-за мнимого дисбаланса. В низконагруженных средах легко может оказаться, что лишь несколько процессоров заняты, поскольку не хватает vCPU, способных нагрузить систему. Попытка выровнять нагрузку в данном случае приведет к ненужным миграциям и снизит производительность.
Например, один vCPU дает 95% нагрузки на pCPU (PA), в то время как остальные pCPU простаивают. Если другой простаивающий pCPU (PB) инициирует миграцию vCPU, то через некоторое время оригинальный pCPU (PA) станет проистаивающим и инициирует миграцию назад. Таким образом приоритезация миграции по нагрузке избавляет нас от этого пинг-понга. Высокая нагрузка на pCPU также означает и высокий вклад в кэш, поскольку у vCPU достаточно времени для разогрева кэша и соотв. высокой доли использования кэша. Это, конечно, не идеальная следственная связь, но вполне разумное предположение. Приоритезация миграций в зависимости от нагрузки на процессор может рассматриваться как необходимое условие для приоритезации миграций на основе рабочего набора в кэше. Точное определение размера рабочего набора в кэше и использование этого для приоритезации миграций - то, что возможно, будет реализовано в следующих версиях гипервизора.
Миграция vCPU начинает приоритезироваться по нагрузке только при условии, что vCPU имеет действительно большую долю в нагрузке на текущий pCPU. Пороговое значение установлено достаточно большим, чтобы разрешать миграции, действительно улучшающие общую производительность. По мере роста нагрузки на систему в целом приоритезация становится все менее вероятной ввиду того, что вклад каждого vCPU в процентном соотношении снижается. Проблема мнимого дисбаланса актуальна только для недозагруженных систем.
Impact on Processor Caching
В ESX4 vCPU виртуальной машины может быть размещен на любом pCPU, поскольку ячейки планировщика ушли в небытие. При работе алгоритма балансировки на основе нагрузки на LLC есть тенденция к разбеганию vCPU одной виртуальной машины по разным LLC. Тем не менее, все они остаются в пределах одного узла NUMA, если машина управляется планировщиком NUMA. Большее количество агрегированного кэша и ширины канала доступа к памяти улучшают производительность для большинства видов нагрузок. Однако нагрузки с интенсивной межпроцессной комуникацией могут страдать от снижения производительности при размещении по разным LLC.
Например, рассмотрим параллельное приложение с малым рабочим набором кэша, но очень частым взаимодействием производитель-потребитель взаимодействием между нитями. Также предполжим, что эти нити распределены по различным vCPU. Если хост недозагружен, то скорее всего vCPU были распределены между различными LLC. Таким образом взаимодействие между нитями приводит к большому количеству cache-miss и общему снижению производительности. Если бы рабочий набор был больше, чем LLC, то политика по-умолчанию улучшила бы производительность.
Относительный эффект большего агрегированного кэша в значительной степени зависит от приложения. Также как и с предыдущим механизмом, динамическое определение типа приложения и изменение политики планировщика на лету бросает новые выовы и будет составлять основу будущей работы. На сегодняшний день можно вручную принудительно задать политику консолидирования кэша.
vSMP Consolidation
Если есть уверенность, что приложение в виртуальной машине получит выигрыш от разделяемого кэша, а не от большего его объема, этот эффект можно достичь при консолидации vSMP. Консолидация vSMP приведет к приоритезации выбора pCPU в пределах LLC для vCPU данной ВМ. Тем не менее, иногда это может и не случиться, в зависимости от доступности pCPU.
Для включения консолидации vSMP необходимо изменить следующий расширенный параметр для ВМ:
Продолжение следует.
Оригинал: "VMware® vSphere™: The CPU Scheduler in VMware ESX® 4.1"
Балансировка нагрузки достигается миграцией vCPU, но после миграции vCPU должен "разогреть" кэш. И в связи с этим реальная стоимость миграции очень сильно зависит от того, требует ли разогрев кэша доступа к оперативной памяти, который не может быть удовлетворен за счет LLC. Иными словами, миграция в пределах LLC значительно дешевле, чем между LLC. Ранее эта внутричиповая топология игнорировалась планировщиком и стоимость миграции считалась одинаковой и фиксированной. Тем не менее, результат был удовлетворительным, поскольку механизм приоритезации миграции между ячейками планировщика (scheduler cell) приводил к высокому уровню между-LLC миграций - ячейка в большинстве случаев равняется одному, как максимум двум LLC.
В ESX4 понятие ячейки планировщика более не используется, а следовательно между-LLC миграции более не приоритезируются. Таким образом механизм балансировки нагрузки занчительно улучшился, поскольку миграция внутри LLC предпочтительнее миграции между LLC. Когда планировщик выбирает pCPU для миграции, локальный процессор, разделяющий LLC, всегда предпочтительнее удаленного, не разделяющего тот же LLC. Тем не менее, миграция на удаленный pCPU все еще возможна, если выбор локального pCPU не может решить проблему балансировки нагрузки.
CPU Load-Based Migration Throttling
В ESX4 vCPU, привносящий значительную нагрузку на текущий pCPU не будет мигрировать, вместо этого планировщик будет в первую очередь мигрировать vCPU с низкой нагрузкой. Данный механизм позволяет снизить количество миграций из-за мнимого дисбаланса. В низконагруженных средах легко может оказаться, что лишь несколько процессоров заняты, поскольку не хватает vCPU, способных нагрузить систему. Попытка выровнять нагрузку в данном случае приведет к ненужным миграциям и снизит производительность.
Например, один vCPU дает 95% нагрузки на pCPU (PA), в то время как остальные pCPU простаивают. Если другой простаивающий pCPU (PB) инициирует миграцию vCPU, то через некоторое время оригинальный pCPU (PA) станет проистаивающим и инициирует миграцию назад. Таким образом приоритезация миграции по нагрузке избавляет нас от этого пинг-понга. Высокая нагрузка на pCPU также означает и высокий вклад в кэш, поскольку у vCPU достаточно времени для разогрева кэша и соотв. высокой доли использования кэша. Это, конечно, не идеальная следственная связь, но вполне разумное предположение. Приоритезация миграций в зависимости от нагрузки на процессор может рассматриваться как необходимое условие для приоритезации миграций на основе рабочего набора в кэше. Точное определение размера рабочего набора в кэше и использование этого для приоритезации миграций - то, что возможно, будет реализовано в следующих версиях гипервизора.
Миграция vCPU начинает приоритезироваться по нагрузке только при условии, что vCPU имеет действительно большую долю в нагрузке на текущий pCPU. Пороговое значение установлено достаточно большим, чтобы разрешать миграции, действительно улучшающие общую производительность. По мере роста нагрузки на систему в целом приоритезация становится все менее вероятной ввиду того, что вклад каждого vCPU в процентном соотношении снижается. Проблема мнимого дисбаланса актуальна только для недозагруженных систем.
Impact on Processor Caching
В ESX4 vCPU виртуальной машины может быть размещен на любом pCPU, поскольку ячейки планировщика ушли в небытие. При работе алгоритма балансировки на основе нагрузки на LLC есть тенденция к разбеганию vCPU одной виртуальной машины по разным LLC. Тем не менее, все они остаются в пределах одного узла NUMA, если машина управляется планировщиком NUMA. Большее количество агрегированного кэша и ширины канала доступа к памяти улучшают производительность для большинства видов нагрузок. Однако нагрузки с интенсивной межпроцессной комуникацией могут страдать от снижения производительности при размещении по разным LLC.
Например, рассмотрим параллельное приложение с малым рабочим набором кэша, но очень частым взаимодействием производитель-потребитель взаимодействием между нитями. Также предполжим, что эти нити распределены по различным vCPU. Если хост недозагружен, то скорее всего vCPU были распределены между различными LLC. Таким образом взаимодействие между нитями приводит к большому количеству cache-miss и общему снижению производительности. Если бы рабочий набор был больше, чем LLC, то политика по-умолчанию улучшила бы производительность.
Относительный эффект большего агрегированного кэша в значительной степени зависит от приложения. Также как и с предыдущим механизмом, динамическое определение типа приложения и изменение политики планировщика на лету бросает новые выовы и будет составлять основу будущей работы. На сегодняшний день можно вручную принудительно задать политику консолидирования кэша.
vSMP Consolidation
Если есть уверенность, что приложение в виртуальной машине получит выигрыш от разделяемого кэша, а не от большего его объема, этот эффект можно достичь при консолидации vSMP. Консолидация vSMP приведет к приоритезации выбора pCPU в пределах LLC для vCPU данной ВМ. Тем не менее, иногда это может и не случиться, в зависимости от доступности pCPU.
Для включения консолидации vSMP необходимо изменить следующий расширенный параметр для ВМ:
sched.cpu.vsmpConsolidate = true.
Продолжение следует.
Оригинал: "VMware® vSphere™: The CPU Scheduler in VMware ESX® 4.1"
среда, 21 декабря 2011 г.
vAdmin.RU и компания Iomega играют в деда Мороза!
Скоро Новый Год и мы решили немножко поиграть в деда Мороза. Компания Iomega нам в этом помогает :)
Итак, на кону два подарка, а ответы принимаются до 27го декабря.

Медиа-плеер Iomega® ScreenPlay® MX получит кто-то из правильно ответивших на вопросы о компании Iomega.

Ответы более не принимаются.
пятница, 9 декабря 2011 г.
Новый облачный учебный курс и сертификация от EMC

Компания EMC добавила в облачный трек Cloud Architect новый учебный курс и сертификацию базового уровня по облакам.
Напомню, что ранее для сертификации по программе EMCCA в качестве базового уровня (Associate) требовался общий курс по управлению информацией EMCISA (E20-001 - Information Storage and Management). Курс безусловно полезный, однако к облакам имеющий отношение отдаленное. Теперь появились специализированный базовый облачный курс Cloud Infrastructure and Services и сертификация EMCCIS (E20-002).
Предполагаемые темы вопросов экзамена EMCCIS:
Journey to the Cloud and Cloud Primer
• Business drivers and characteristics of Cloud
• Phases and activities of journey to the Cloud
• Cloud deployment and service models
• Cloud benefits and challenges
Classic Data Center
• RAID Technology and intelligent storage system
• Storage Networking options: DAS, FC and IP SAN, NAS, FCoE, and unified storage
• Backup and Replication
• Data Center management in classic environment
Virtualized Data Center
• Compute virtualization
• Storage virtualization and virtual provisioning
• Network virtualization including virtual LAN and SAN
• Desktop and application virtualization
• Business Continuity in a virtualized environment
Cloud Services and Management
• Cloud infrastructure, service creation and management
• Cloud security concerns, solution, and best practices
• Best practices and consideration for migration to the Cloud
Помимо этого появился учебный курс высшего уровня Expert (EMCCAe) - IT-as-a-Service Planning and Design, однако экзамен на этот уровень ожидается только в феврале 2012.
This expert-level course provides the knowledge and skills necessary to design cloudbased IT-as-a-Service (ITaaS) solutions. Building on the skills acquired in the Virtualized Data Center and Cloud Infrastructure specialist-level course, it focuses on business, organizational, governance, technology, and service management aspects from a designcentric perspective. By utilizing lecture, discussions, case studies, design examples, and a series of interactive problem-solving labs, students will learn to design solutions which transform business operations and virtualized data centers into ITaaS environments. The course is applicable to enterprise, service provider, and existing virtualized data center operations considering ITaaS. This course uses an open approach focusing on core concepts, principals, and technologies rather than specific products. To provide context, the course includes EMC specific examples and case studies.
vSphere 5 Storage DRS и другие видео от EMC Proven Solutions
Канал EMCProvenSolutions радует новыми видео:
vSphere 5 Storage DRS based on Datastore Capacity Utilization
vSphere 5 Storage DRS based on Datastore Capacity Utilization
Вопросы дизайна СХД для vSphere 5 при использовании Storage DRS
В vSphere 5 представлено огромное количество новых функций, множество из которых еще, увы, не освещено. Хотелось бы рассказать о новых функциях, так, или иначе, касающихся вопросов дизайна СХД – Storage DRS и кластера хранилищ.
Storage DRS – механизм, о котором в своё время ходило много слухов. Является развитием технологии Distributed Resource Scheduling, и позволяет мигрировать файлы виртуальных машин между хранилищами, входящими в один кластер для балансировки нагрузки на СХД. Несмотря на то, что Storage DRS позволяет отслеживать производительность ВМ, не нужно путать эту функцию с Storage IO Control (SIOC). Также интегрируется с VASA (VMware vSphere Aware Storage API), о котором ниже.
Storage DRS – механизм, о котором в своё время ходило много слухов. Является развитием технологии Distributed Resource Scheduling, и позволяет мигрировать файлы виртуальных машин между хранилищами, входящими в один кластер для балансировки нагрузки на СХД. Несмотря на то, что Storage DRS позволяет отслеживать производительность ВМ, не нужно путать эту функцию с Storage IO Control (SIOC). Также интегрируется с VASA (VMware vSphere Aware Storage API), о котором ниже.
понедельник, 5 декабря 2011 г.
VMware User Group
Мы сделали это! Предварительные планы на следующий год по VMware User Group одобрены!
Итак, мы планируем проведение встреч VMware User Group в первом полугодии в: Москве, Санкт-Петербурге, Екатеринбурге и Новосибирске! И я вам гарантирую, встреча VMware User Group Russia в Москве будет категории Super Heavy Weight.
Но нам требуется ваша помощь, помощь тех, кто приходит слушать наши доклады и делиться своим опытом. Впрочем, мы просим от вас сделать лишь небольшое усилие, зарегистрироваться в глобальной организации VMware User Group вот здесь: www.myvmug.org.
Все подробности грядущих встреч будут публиковаться по мере поступления здесь.
И кстати говоря, мы только что открыли филиал VMware User Group в Киеве!
Итак, мы планируем проведение встреч VMware User Group в первом полугодии в: Москве, Санкт-Петербурге, Екатеринбурге и Новосибирске! И я вам гарантирую, встреча VMware User Group Russia в Москве будет категории Super Heavy Weight.
Но нам требуется ваша помощь, помощь тех, кто приходит слушать наши доклады и делиться своим опытом. Впрочем, мы просим от вас сделать лишь небольшое усилие, зарегистрироваться в глобальной организации VMware User Group вот здесь: www.myvmug.org.
Все подробности грядущих встреч будут публиковаться по мере поступления здесь.
И кстати говоря, мы только что открыли филиал VMware User Group в Киеве!
вторник, 11 октября 2011 г.
А что делает VMware, кроме Workstation
Обновился и расширился список продуктов VMware с кратким описанием. Теперь можно точно сказать, что жалобы вида “У меня не работает VMware 4” не сообщают ровно никакой информации :)
понедельник, 10 октября 2011 г.
Управляем СХД EMC из VMware vCenter c помощью VSI 5 Plug-In
Канал EMCProvenSolutions радует новым видео.
Как выглядит управление СХД EMC из клиента vSphere с бесплатным плагином VSI (Virtual Storage Integrator):
Кстати, VSI 5 полностью поддерживает vSphere 5 :)
Влияние снапшотов на производительность - 2
Влияние снапшотов на производительность - 1
Результаты тестов: Снапшот на перегруженных дисках в деталях
Из предыдущего графика можно извлечь информацию о влиянии снапшота, и вот как это выглядит:
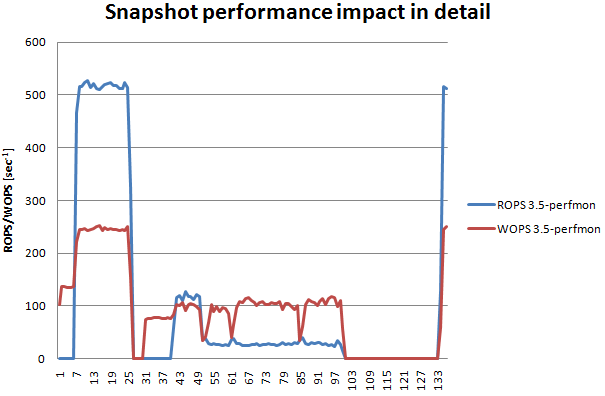
Здесь отлично видна производительность дисковой системы с точки зрения ВМ. А ВМ, как вы помните, пытается нагрузить диски по полной программе – и на чтение и на запись. В начале ВМ смогла получить одновременно 510 ROPS и 250 WOPS (7-25). Затем в точке 30 был создан снапшот, и после того, как IOmeter создал свой тестовый файл, производительность установилась (43-49) на уровне 110 ROPS / 100 WOPS. Впечатляет, не правда ли?
Затем мы удаляем (пытаемся) снапшот в точке 50. Диски остаются перегруженными, и вдобавок VMware накидывает еще больше операций чтения и записи для коммита снапшота. Как итог, производительность чтения проваливается до 28 ROPS. Если сравнить с начальными 510 ROPS, то финальная производительность оказывается на уровне 5.5%!!!
пятница, 7 октября 2011 г.
Пляски вокруг снапшотов
Как вы уже знаете, с точки зрения дисковой производительности снапшоты виртуальных машин являются безусловным злом.
Однако есть ситуации, когда может захотеться разделить базовые диски и дельта-файлы для снапшотов по различным датасторам. Например, Linked Clones работают именно так. Так как же это сделать?
В vSphere 4 для этого используется расширенный параметр workingDir.
Однако в 5.0 его влияние изменено для обспечения логики работы Storage DRS, и теперь он влияет только на файл снапшота .vmsn, а дельты сохраняются вместе с базовыми дисками, чтобы гарантировать единую производительность дисковой системы для ВМ. В этом случае требуется еще один расширенный параметр:
snapshot.redoNotWithParent = "TRUE"
Правда в этом случае вам придется воздержаться от использования Storage vMotion для данной ВМ, посколько после перемещения параметр workingDir будет сброшен. Соотв. Storage DRS так же исключается.
Можно ограничить общее количество снапшотов:
snapshot.maxSnapshots = "n"
Тем не менее, я лично не рекомендую использовать данные параметры, как и любые другие расширенные параметры до тех пор, пока это не становится совершенно необходимо и не испробованы другие средства. В большинстве случаев сам факт того, что вы собираетесь их использовать, говорит об ошибке на ранних стадиях или даже в дизайне решения. Хотя, безусловно, в некоторой небольшой доле случаях их использование оправдано.
За указание на существование параметров благодарность Максиму Мошкову. И, разумеется, не забывайте о существовании замечательного русскоязычного форума VMware :)
понедельник, 26 сентября 2011 г.
EMC Cloud Architect
Коллеги, хочу поделиться впечатлением от курса Virtualized Data Center and Cloud Infrastructure, который прослушал месяц назад в рамках программы Cloud Architect.
Общее впечатление: настоятельно рекомендую всем, кто занимается/интересуется чем-то большим, чем простое администрирование платформы виртуализации.
А теперь подробнее. Насколько мне известно (хотя конечно могу и ошибаться), это один из первых курсов, предлагающих обучение по облакам в целом. При этом акцент именно на облаках, на определении и концепции. Чем облачный сервис отличается от не облачного?
Это НЕ технический курс и он НЕ о том, какие продукты должны лежать в основе облака. Поскольку курс от EMC, то в качестве примеров разумеется используются продукты EMC и VMware, но упоминаются достаточно поверхностно, лишь в связи с тем, что они обеспечивают - Data Mobility, Resource Pooling и так далее. Технари, ожидающие детального "вскрытия" облака и тонкой хирургии в его внутренностях, скорее всего будут разочарованы. Я тоже сначала слегка был.
Однако суть курса не в этом, продуктовые курсы с тонкой настройкой и скрытыми параметрами в конфигурационных файлах вы всегда можете взять отдельно. Для 100% технаря вроде меня данный курс полезен тем, что позволяет уйти от техники к концепции облака, от мегагерцев к услугам, к уровням обслуживания.
Без всяких сомнений, если вас интересует рост от инженера до архитектора со специализацией в облачных сервисах - курс полезен.
Курс предполагает сертификацию EMCCA (E20-018 Virtualized Data Center and Cloud Infrastructure Design Specialist) - уровень EMC Proven Professional Specialist. Для сдачи экзамена необходима базовая сертификация EMCISA (E20-001 Information Storage and Management).
Производительность СХД. Часть третья
Пару лет назад на западных блогах, специализирующихся на технологиях VMware, было очень популярно писать как важно выравние (или же alignment), и как вредит производительности отсутствие оного. До нас эта тенденция особо не дошла, но периодически эта тема опять всплывает без ясного объяснения, что же это такое.
Физическая адресация
В первой части говорилось о подноготной жёстких дисков - какие факторы внутри самих дисков влияют на их производительность, при этом упустив вопрос строения и адресации данных на диске при низкоуровневом форматировании.
Физическая адресация
В первой части говорилось о подноготной жёстких дисков - какие факторы внутри самих дисков влияют на их производительность, при этом упустив вопрос строения и адресации данных на диске при низкоуровневом форматировании.
четверг, 1 сентября 2011 г.
VMware vSphere 5 - Using Image Builder To Create Custom ISO
Канал EMCProvenSolutions радует новым видео:
среда, 31 августа 2011 г.
vSMP Fault Tolerance
For a long time VMware Fault Tolerance was only supported on a single vCPU VM. Today we witnessed a change: During the BCO2874 session we got a first look on the prototype of the SMP enabled Fault Tolerance. Cool!
Что такое FT?
Как многие :) уже знают, Fault Tolerance (FT) создает теневую копию виртуальной машины на другом узле vSphere, такк что при смерти основного узла, управление полностью передается на теневую машину и она подхватывает все операции без простоя и перезагрузок.
Звучит очень интригующе, но в реальность есть много ограничений. Например FT могла обеспечить отказоустойчивость только однопроцессорных машин, многопроцессорные машины запустить было невозможно. До сегодняшнего дня.
VMworld 2011 update
Немного новостей в прямом эфире с VMworld 2011.
Steven Herrod рассказал куда мы двигаемся и что нового нас ждет.
Новый подход к работе пользователей
У пользователей больше нет "просто десктопа", взаимодействие становится все шире. Анонсировано следующее:
ThinApp factory & Horizon
ThinApp factory позволит использовать приложения, не таская за собой целый VDI десктоп. По мере того, как SaaS приложения становятся стандартом, их можно просто закинуть в "пузырь" ThinApp. Horizon - централизованное решение, дающее возможность пользователям подключаться напрямую к SaaS приложениям, используя доменную учетную запись.
Project Octopus
Используете DropBox? Наверное да. Разрешено ли использовать DropBox? Скорее всего нет, вопрос безопасности стоит достаточно остро. Но если индустрия не найдет варианта доставки сервиса, пользователи найдут свой путь, как например DropBox. Проект Octopus посвящен именно этому, но только как корпоративное решение. Безопасный доступ к вашим данным как в частном, так и публичном облаке.
Horizon Mobile
Проект, ранее известный как MVP (Mobile Virtualization Platform). Мы слышали о нем еще несколько лет назад, но он так и не был доведен до публичного релиза. До сегодняшнего дня. И наконец, официально объявляется о возможности запуска виртуальной машины на мобильном телефоне. По нажатию одной кнопки запускается виртуальный экземпляр корпоративного телефона. Да, это еще один шаг в сторону "bring your own device" и реализации безопасного доступа с недоверенных устройств.
AppBlast
AppBlast позволит вам, например, открыть для чтения Excel файл без того, чтобы устанавливать Excel на компьютер. AppBlast будет конвертировать данные на лету в чистый HTML.
Клиент iPad
Управляем средой vSphere c iPad'а :)
VMware Go и другие SMB фишки
VMware Go предназначена для малого бизнеса без выделенных системных администраторов (или без квалифицированных администраторов). Полностью web based, автоматически просканирует сеть и поможет сконвертировать текущие задачи и перенести их на ESXi. Вряд ли в ближайшее время будет позльзоваться популярностью в России, но посмотрим :)
VMware VSA - о ней уже говорили, виртуальный модуль для организации виртуального разделяемого хранилища на базе локальных дисков ESXi сервера. Многие крупные компании с большим количеством региональных офисов так же буду весьма заинтересованы в этом решении.
Для того же сегмента малого бизнеса анонсирована функция Host Based Replication (HBR) при использовании SRM5.
Новая сетевая фишка: VXLAN
Совершенно новая сетевая функциональность, над которой VMware работала несколько лет. Попросту говоря, это упаковка L2 сеть в L3.
Интересная тенеденция, персона (профиль пользователя) теперь оторван от местоположения (десктопа), так же как и номер мобильного телефона оторван от физического местоположения. И теперь мы больше не привязаны к конкретной точке входа в сеть!
Steven Herrod рассказал куда мы двигаемся и что нового нас ждет.
Новый подход к работе пользователей
У пользователей больше нет "просто десктопа", взаимодействие становится все шире. Анонсировано следующее:
ThinApp factory & Horizon
ThinApp factory позволит использовать приложения, не таская за собой целый VDI десктоп. По мере того, как SaaS приложения становятся стандартом, их можно просто закинуть в "пузырь" ThinApp. Horizon - централизованное решение, дающее возможность пользователям подключаться напрямую к SaaS приложениям, используя доменную учетную запись.
Project Octopus
Используете DropBox? Наверное да. Разрешено ли использовать DropBox? Скорее всего нет, вопрос безопасности стоит достаточно остро. Но если индустрия не найдет варианта доставки сервиса, пользователи найдут свой путь, как например DropBox. Проект Octopus посвящен именно этому, но только как корпоративное решение. Безопасный доступ к вашим данным как в частном, так и публичном облаке.
Horizon Mobile
Проект, ранее известный как MVP (Mobile Virtualization Platform). Мы слышали о нем еще несколько лет назад, но он так и не был доведен до публичного релиза. До сегодняшнего дня. И наконец, официально объявляется о возможности запуска виртуальной машины на мобильном телефоне. По нажатию одной кнопки запускается виртуальный экземпляр корпоративного телефона. Да, это еще один шаг в сторону "bring your own device" и реализации безопасного доступа с недоверенных устройств.
AppBlast
AppBlast позволит вам, например, открыть для чтения Excel файл без того, чтобы устанавливать Excel на компьютер. AppBlast будет конвертировать данные на лету в чистый HTML.
Клиент iPad
Управляем средой vSphere c iPad'а :)
VMware Go и другие SMB фишки
VMware Go предназначена для малого бизнеса без выделенных системных администраторов (или без квалифицированных администраторов). Полностью web based, автоматически просканирует сеть и поможет сконвертировать текущие задачи и перенести их на ESXi. Вряд ли в ближайшее время будет позльзоваться популярностью в России, но посмотрим :)
VMware VSA - о ней уже говорили, виртуальный модуль для организации виртуального разделяемого хранилища на базе локальных дисков ESXi сервера. Многие крупные компании с большим количеством региональных офисов так же буду весьма заинтересованы в этом решении.
Для того же сегмента малого бизнеса анонсирована функция Host Based Replication (HBR) при использовании SRM5.
Новая сетевая фишка: VXLAN
Совершенно новая сетевая функциональность, над которой VMware работала несколько лет. Попросту говоря, это упаковка L2 сеть в L3.
Интересная тенеденция, персона (профиль пользователя) теперь оторван от местоположения (десктопа), так же как и номер мобильного телефона оторван от физического местоположения. И теперь мы больше не привязаны к конкретной точке входа в сеть!
четверг, 18 августа 2011 г.
Производительность СХД. Часть вторая.
Итак, с основными параметрами жёстких дисков мы уже разобрались. Второй этап – выбор типа RAID массива. Рассмотрим основные типы RAID массивов, их плюсы и минусы, а также вопрос о производительности наиболее часто используемых типов RAID, и их накладных расходах на запись.
четверг, 11 августа 2011 г.
Производительность СХД. Часть первая.
Мощность процессоров в серверах за последние 10 лет выросла в десятки раз, количество оперативной памяти тоже, тогда как у жёстких дисков производительность растёт строго линейно и весьма медленно. И если с процессорами и памятью всё просто и понятно – чем больше, тем лучше, то с дисками всё намного сложнее. И чаще всего производительность дисков и СХД является узким местом виртуальной инфраструктуры из-за неправильного сайзинга.
Сегодня мы поговорим о базовых факторах, определяющих производительность жестких дисков.
Сегодня мы поговорим о базовых факторах, определяющих производительность жестких дисков.
понедельник, 8 августа 2011 г.
пятница, 5 августа 2011 г.
NUMA для vCPU в vSphere 5
Сегодня я бы хотел рассказать о мало освещаемой в блогосфере функции vSphere 5 – virtual NUMA. Что такое NUMA Антон уже описывал около года назад. Технология же virtual NUMA (vNUMA) позволяет гипервизору экспортировать в виртуальную машину данные о NUMA физического сервера. Преимущество этой технологии в том, что все современные ОС уже знают о NUMA и умеют с ней правильно работать, и, как следствие, смогут использовать данные о NUMA для получения максимальной производительности.
Для использования vNUMA необходимо, чтобы ВМ использовала vHW версии 8, а, во-вторых, vNUMA уже автоматически активирована для виртуальных машин с количеством vCPU от 8.
Еще один нюанс состоит в том, что если в ВМ ядер на сокет больше 1го, то размер vNUMA будет равен количеству ядер в сокете. Если же по какой-либо причине Вы выставили 1 ядро на сокет, то параметры vNUMA будут соответствовать NUMA ноде сервера.
Также существует набор тонких настроек vNUMA, изменять которые можно в разделе Aвvanced Settings для ВМ:
cpuid.coresPerSocket - Определяет количество ядер на сокете. Также отвечает за размер vNUMA, если таковая используется. Можно настраивать, если известна точная конфигурация NUMA на сервере.
numa.vcpu.maxPerVirtualNode - Если предыдущая чётко указывает количество ядер на узел, то это настройка указывает максимально возможное. Нельзя использовать их обе одновременно.
numa.autosize - каждый раз при включении ВМ размер vNUMA подгоняется под размер NUMA узлов сервера.
numa.autosize.once - то же самое, только работает один раз. Исключение: если из запущенной хотя бы 1 раз ВМ сделать шаблон – виртуальная машина, развёрнутая из этого шаблона будет иметь такую же vNUMA архитектуру, что и источник для шаблона.
numa.vcpu.min - минимальное количество vCPU, необходимых для создания vNUMA.
numa.vcpu.maxPerMachineNode - максимальное количество vCPU одной ВМ, которые могут работать в рамках одного физического NUMA узла.
numa.vcpu.maxPerClient - количество vCPU в NUMA клиенте. Клиент, в свою очередь - группа vCPU, которые обрабатываются как vNUMA, то есть как 1 объект. По умолчанию, 1 vNUMA является 1 клиентом, но если vNUMA больше pNUMA, то vNUMA может быть разбита не несколько меньших vNUMA клиентов.
numa.nodeAffinity - номера физических NUMA узлов, на которых исполяется виртуальная машина. Крайне не рекомендуется менять эту настройку, так как vmkernel не сможет нормально балансировать такую виртуальную машину между NUMA нодами.
Для использования vNUMA необходимо, чтобы ВМ использовала vHW версии 8, а, во-вторых, vNUMA уже автоматически активирована для виртуальных машин с количеством vCPU от 8.
Еще один нюанс состоит в том, что если в ВМ ядер на сокет больше 1го, то размер vNUMA будет равен количеству ядер в сокете. Если же по какой-либо причине Вы выставили 1 ядро на сокет, то параметры vNUMA будут соответствовать NUMA ноде сервера.
Также существует набор тонких настроек vNUMA, изменять которые можно в разделе Aвvanced Settings для ВМ:
cpuid.coresPerSocket - Определяет количество ядер на сокете. Также отвечает за размер vNUMA, если таковая используется. Можно настраивать, если известна точная конфигурация NUMA на сервере.
numa.vcpu.maxPerVirtualNode - Если предыдущая чётко указывает количество ядер на узел, то это настройка указывает максимально возможное. Нельзя использовать их обе одновременно.
numa.autosize - каждый раз при включении ВМ размер vNUMA подгоняется под размер NUMA узлов сервера.
numa.autosize.once - то же самое, только работает один раз. Исключение: если из запущенной хотя бы 1 раз ВМ сделать шаблон – виртуальная машина, развёрнутая из этого шаблона будет иметь такую же vNUMA архитектуру, что и источник для шаблона.
numa.vcpu.min - минимальное количество vCPU, необходимых для создания vNUMA.
numa.vcpu.maxPerMachineNode - максимальное количество vCPU одной ВМ, которые могут работать в рамках одного физического NUMA узла.
numa.vcpu.maxPerClient - количество vCPU в NUMA клиенте. Клиент, в свою очередь - группа vCPU, которые обрабатываются как vNUMA, то есть как 1 объект. По умолчанию, 1 vNUMA является 1 клиентом, но если vNUMA больше pNUMA, то vNUMA может быть разбита не несколько меньших vNUMA клиентов.
numa.nodeAffinity - номера физических NUMA узлов, на которых исполяется виртуальная машина. Крайне не рекомендуется менять эту настройку, так как vmkernel не сможет нормально балансировать такую виртуальную машину между NUMA нодами.
понедельник, 18 июля 2011 г.
VMware vSphere SRM Site Failover using EMC RecoverPoint Replication
Коллеги, рад сообщить, что на youtube появился канал EMC Proven Solutions с видеообзорами best practice.
Например, вот так выглядит интеграция VMware Site Recovery Manager и EMC RecoverPoint.
Например, вот так выглядит интеграция VMware Site Recovery Manager и EMC RecoverPoint.
воскресенье, 17 июля 2011 г.
vCat ищет себе vAdmin'а

Кот Канопус очень хочет найти себе хорошего Человека. Шотландский вислоухий, 1 год, очень общительный и ласковый. Отдается бесплатно, лишь бы человек хороший был.
Причина - мой график командировок.
пятница, 15 июля 2011 г.
vSphere 5. Storage vMotion.
Технология Storage vMotion позволяет мигрировать включенные ВМ между датасторами нон-стоп, без прерывания сервиса. Впервые она была представлена как механизм миграции ВМ с VMFS-2 на VMFS-3 без простоя ВМ при апгрейде с ESX 2.x на ESX 3.0.1. Мы даже не называли ее тогда Storage vMotion, а использовали что-то вроде Upgrade vMotion.
Быстро стало понятно, что для данной технологии существует множество применений - помощь при использовании различных уровней хранения данных, миграция ВМ при обслуживании СХД или вводе в эксплуатацию новой СХД / выводе из эксплуатации старой.
Механизмы работы Storage vMotion претерпели большое количество изменений с первоначального варианта. Сейчас, в vSphere 5.0, мы представляем новый улучшеный вариант, значительно повышающий производительность и надежность при миграции ВМ.
Быстро стало понятно, что для данной технологии существует множество применений - помощь при использовании различных уровней хранения данных, миграция ВМ при обслуживании СХД или вводе в эксплуатацию новой СХД / выводе из эксплуатации старой.
Механизмы работы Storage vMotion претерпели большое количество изменений с первоначального варианта. Сейчас, в vSphere 5.0, мы представляем новый улучшеный вариант, значительно повышающий производительность и надежность при миграции ВМ.
Размер блока и раздела VMFS
На днях к виртуальной машине (vCenter 4.1, ESX4.1) подключаю RDM-раздел и получаю ошибку "File[Name Datastore]nameVM.nameVM.vmdk is larger than the maximum size supported by datastore Name Datastore".
Ищу на http://kb.vmware.com/, получаю знание 1029697, где говорится правильно выбирайте VMFS block size. Вижу, где прокол (см. максимумы). Ограничение относится к VMFS.
Но самое интересное, что за год до этого на ESX 3.5 удалось подключить раздел размером 1TB, а виртуальная машина была на таком же VMFS-разделе, и после обновления на 4.1 прекрасно работает.. Возможно, дело в версии hardware виртуальной машины (как-нибудь проверю). Но вопрос не в этом. До этого случая я никогда не обращал внимание на вопрос выбора размера блока VMFS и создавал datastore по умолчанию (block size 1MB). Обозначилась необходимость понимать, на что влияют размер блока, размер раздела, и учитывать это при планировании хранилища.
Ищу на http://kb.vmware.com/, получаю знание 1029697, где говорится правильно выбирайте VMFS block size. Вижу, где прокол (см. максимумы). Ограничение относится к VMFS.
Но самое интересное, что за год до этого на ESX 3.5 удалось подключить раздел размером 1TB, а виртуальная машина была на таком же VMFS-разделе, и после обновления на 4.1 прекрасно работает.. Возможно, дело в версии hardware виртуальной машины (как-нибудь проверю). Но вопрос не в этом. До этого случая я никогда не обращал внимание на вопрос выбора размера блока VMFS и создавал datastore по умолчанию (block size 1MB). Обозначилась необходимость понимать, на что влияют размер блока, размер раздела, и учитывать это при планировании хранилища.
среда, 13 июля 2011 г.
vSphere 5. Лицензирование.
VMware ввела новую схему лицензирования в vSphere 5, и твиттер буквально кипит обсуждениями.

Что же там такого изменилось?

Что же там такого изменилось?
пятница, 8 июля 2011 г.
Имеет ли смысл дефрагментация диска в гостевой ОС?
Тема дефрагментации файловой системы периодически всплывает то на форуме, то просто в почте.
Так нужна ли дефрагментация в виртуальном мире, которая как известно, сильно помогает в мире физическом?
Начем с того, что такое фрагментация вообще и каково ее влияние на производительность. Итак, фрагментация - ситуация, когда блоки большого файла разбросаны по физическому диску в случайном порядке. Влияние фрагментации отлично видно на обычной домашней машине с одним жестким диском и большим количеством больших файлов (кино, фото и т.д.). В этом случае для чтения файла (например при копировании) головка диска не может осуществлять линейное последовательное чтение на максимальной скорости, а вынуждена метаться между блоками. Разумеется, все то время, что головка перемещается к нужному цилиндру и ждет начала блока с данными, чтения не происходит. Итог - снижение скорости чтения. Иногда кардинальное снижение, если файл оказался разбит на множество блоков малого размера.
Лечение - путем последовательных чтения/записи переместить по диску блоки файла таким образом, чтобы в максимальной степени сделать их последовательными и соотв. свести перемещания головки к минимуму.
Просто, очевидно и ведет к легко измеримому преимуществу. Но так ли это в виртуальном мире?
А вот здесь как раз зарыт бегемот.
Так нужна ли дефрагментация в виртуальном мире, которая как известно, сильно помогает в мире физическом?
Начем с того, что такое фрагментация вообще и каково ее влияние на производительность. Итак, фрагментация - ситуация, когда блоки большого файла разбросаны по физическому диску в случайном порядке. Влияние фрагментации отлично видно на обычной домашней машине с одним жестким диском и большим количеством больших файлов (кино, фото и т.д.). В этом случае для чтения файла (например при копировании) головка диска не может осуществлять линейное последовательное чтение на максимальной скорости, а вынуждена метаться между блоками. Разумеется, все то время, что головка перемещается к нужному цилиндру и ждет начала блока с данными, чтения не происходит. Итог - снижение скорости чтения. Иногда кардинальное снижение, если файл оказался разбит на множество блоков малого размера.
Лечение - путем последовательных чтения/записи переместить по диску блоки файла таким образом, чтобы в максимальной степени сделать их последовательными и соотв. свести перемещания головки к минимуму.
Просто, очевидно и ведет к легко измеримому преимуществу. Но так ли это в виртуальном мире?
А вот здесь как раз зарыт бегемот.
понедельник, 4 июля 2011 г.
Поиск соавторов
Коллеги,
В силу высокой загрузки, как вы можете видеть, постить что-то интересное удается не так часто, как хотелось бы. Поэтому блог "Записки виртуального админа" объявляет поиск соавторов - как на постоянной основе, так и для публикации одной-двух статей.
Если вы еще не решили, хотите ли вести постоянный блог, но есть материал и интересные случаи, которыми хочется поделиться с сообществом - велкам.
Способы связи - в контактах.
P.S. по итогам года для соавторов будут вручены призы :)
В силу высокой загрузки, как вы можете видеть, постить что-то интересное удается не так часто, как хотелось бы. Поэтому блог "Записки виртуального админа" объявляет поиск соавторов - как на постоянной основе, так и для публикации одной-двух статей.
Если вы еще не решили, хотите ли вести постоянный блог, но есть материал и интересные случаи, которыми хочется поделиться с сообществом - велкам.
Способы связи - в контактах.
P.S. по итогам года для соавторов будут вручены призы :)
вторник, 28 июня 2011 г.
VMFS: FC & iSCSI
Недавно задали вопрос: можно ли расшарить VMFS на хосты по разным протоколам? Т.е. к одному и тому же LUN'у один хост обращается по Fiber Channel, а второй по iSCSI.
Согласно официальному документу "EMC CLARiiON Integration with VMware ESX":
Иными словами, при использовании систем EMC CLARiiON / VNX это возможно. Кстати, документ очень интересен с технической точки зрения и рекомендуется к прочтению, даже если у вас система не EMC.
Согласно официальному документу "EMC CLARiiON Integration with VMware ESX":
VMware VMotion is supported with Fibre Channel and iSCSI connectivity to CLARiiON storage systems. Furthermore, VMware VMotion is supported in configuration where both of the following occur:
* A single LUN is presented to two VMware ESX server nodes.
* The ESX server nodes are in a cluster in which one node accesses the LUN via FC and the other node accesses the LUN via iSCSI.
CLARiiON storage systems preserve the LUN HLU number across both protocols. Therefore, when a LUN is presented via FC to one host and iSCSI to another, a false snapshot is not detected.
Иными словами, при использовании систем EMC CLARiiON / VNX это возможно. Кстати, документ очень интересен с технической точки зрения и рекомендуется к прочтению, даже если у вас система не EMC.
вторник, 7 июня 2011 г.
VMware Forum Kiev - 10 июня
Коллеги,
10го июня буду в Киеве на VMware Forum. Приходите, будет интересно.
P.S. вкусные напитки в хорошей компании после официальной части категорически приветствуются :)
10го июня буду в Киеве на VMware Forum. Приходите, будет интересно.
P.S. вкусные напитки в хорошей компании после официальной части категорически приветствуются :)
суббота, 21 мая 2011 г.
Влияние снапшотов на производительность - 1
Зачастую пользователи жалуются: "Если я нажимаю "Delete snapshot" - все просто встает!" Причем у кого-то действительно все сильно тормозит, а кто-то практически не замечает, что вообще что-то происходит.
Так что же происходит со снапшотами и как они влияют на производительность?
Описание тестовой среды:
Обращаю ваше внимание, что и конфигурационные файлы и диск для измерений находятся на локальных дисках, т.е. все файлы снапшота тоже будут находиться на локальных дисках. Поскольку загрузочный диск ВМ в режиме independent - снапшот к нему не применяется и соотв. влияния на производительность он не оказывает.
Так что же происходит со снапшотами и как они влияют на производительность?
Описание тестовой среды:
- Windows 2003-R2-SP2 ВМ (32 bit);
- 1 vCPU;
- 2048 MB RAM;
- 5 GB загрузочный диск в режиме "independent" - SAN;
- Конфигурационные файлы ВМ и 4 GB диск для измерений на локальных дисках (10K RAID1);
- IOmeter (version 2006.07.27);
- Perfmon измеряет reads/writes на PhysicalDisk с интервалом 20 секунд;
- ВМ созданы на ESX3.5 и 4.0 для сравнения.
Обращаю ваше внимание, что и конфигурационные файлы и диск для измерений находятся на локальных дисках, т.е. все файлы снапшота тоже будут находиться на локальных дисках. Поскольку загрузочный диск ВМ в режиме independent - снапшот к нему не применяется и соотв. влияния на производительность он не оказывает.
среда, 11 мая 2011 г.
VMworld Sessions
VMware открыла голосование для выбора сессий на VMworld.
https://vmworld2011.wingateweb.com/scheduler/publicVoting.do
Моя сессия – 3332 :)
https://vmworld2011.wingateweb.com/scheduler/publicVoting.do
Моя сессия – 3332 :)
среда, 13 апреля 2011 г.
VMware vExpert 2011
Напомню, что vExpert - это не техническое звание как VCP и не требует каких-либо экзаменов. Звание vExpert присуждается за вклад в развитие сообщества блоггерам, авторам книг, лидерам VMware User Group, спикерам и организаторам мероприятий, лидерам форумов - иными словами всем тем, кто тратит свое время и делится своими знаниями с сообществом.
VMware vExpert'ы получают доступ к бетам продуктов, бесплатный доступ к контенту vmworld.com, доступ к закрытому форуму vExpert, лицензиям. В прошлом году звание vExpert получили около 350 человек, из них 6 в России и СНГ.
Вот здесь вы можете заявить свою активность в сообществе, либо номинировать того, кто, по вашему мнению, заслуживает звания vExpert за свою активность в 2010.
VMware User Group - Тбилиси, Грузия
Рад сообщить, что 22 апреля в Тбилиси пройдет первая встреча VMware User Group Georgia. Организатор мероприятия - Сандро Галдава с моей посильной помощью.
За поддержку спасибо компании EMC.
Регистрация здесь.
Приходите, будет интересно :)
За поддержку спасибо компании EMC.
Регистрация здесь.
Приходите, будет интересно :)
суббота, 9 апреля 2011 г.
Бесплатная книга о защите данных в средах VMware
Компания Veeam сделала прекрасный подарок всему сообществу, выложив в открытый доступ книгу известного специалиста в области виртуальных сред VMware "Top 10 Best Practices for VMware Data Protection by VMware vExpert Eric Siebert".
Eric Siebert is an IT industry veteran, author and blogger with more than 25 years of experience, most recently specializing in server administration and virtualization. He is a very active member of the VMware VMTN support forums, where he's attained the elite Guru status by helping others with their virtualization-related challenges.
суббота, 26 марта 2011 г.
EMC Record Breaking Tour в Екатериннбурге и Новосибирске
Рад сообщить, что 5го апреля в Екатеринбурге и 7го апреля в Новосибирске состоятся семинары, посвященные новой линейке систем хранения данных EMC. Я на них присутствую, и даже не исключено, что выступаю. Приходите, будет интересно.
В любом случае буду готов ответить на ваши вопросы в кулуарах и рассказать про интеграцию СХД EMC и продуктов VMware.
P.S. и не откажусь от общения в неофициальном режиме за кружечкой пива после мероприятия :)
В любом случае буду готов ответить на ваши вопросы в кулуарах и рассказать про интеграцию СХД EMC и продуктов VMware.
P.S. и не откажусь от общения в неофициальном режиме за кружечкой пива после мероприятия :)
понедельник, 14 марта 2011 г.
Тонкие диски и фрагментация VMFS
На форуме VMTN часто поднимается миф о фрагментации VMFS и ее влиянии на дисковую производительность.
При создании тома VMFS вы выбираете размер блока форматирования (1, 2, 4 или 8 МБ). Этот размер блока влияет на то, как гипервизор будет выделять место для VMDK файлов. Для толстых дисков - размер блока, подлежащего заполнению нулями при первом доступе, для тонких - соотв. еще и размер блока для роста.
Так значит тонкие диски в сочетании с маленьким размером блока приведут к фрагментации? Да, это более чем возможно. Однако, вопрос должен звучать: а приведет ли это к снижению производительности? И ответ - нет. Прежде всего, размер блока форматирования VMFS не имеет никакого отношения к вводу-выводу гостевой ОС. Скажем, у вас обычная ВМ с Windows и эта ВМ читает и пишет блоками по 8кБ на томе с 1МБ блоками. Гипервизор не будет читать блоками по 1 МБ, поскольку это вызовет серьезную деградацию общей производительности. Нет, гипервизор передаст СХД запрос гостевой ОС, и СХД в свою очередь будет действовать в соответствии с собственными настройками. Вероятно люди беспокоятся о том, что фрагментации повлияет на последовательные чтение / запись, но подумайте секунду-две. О каком последовательном вводе-выводе мы говорим, если смотреть со стороны СХД? Множество хостов, на каждом из которых не одна ВМ, обращающихся к целой куче виртуальных дисков, размазанных по один Ньютон знает какому количеству шпинделей. Последовательный ввод-вывод вдруг оказывается не таким уж последовательным, не так ли?
Оригинал: Duncan Epping (yellow-bricks.com)
При создании тома VMFS вы выбираете размер блока форматирования (1, 2, 4 или 8 МБ). Этот размер блока влияет на то, как гипервизор будет выделять место для VMDK файлов. Для толстых дисков - размер блока, подлежащего заполнению нулями при первом доступе, для тонких - соотв. еще и размер блока для роста.
Так значит тонкие диски в сочетании с маленьким размером блока приведут к фрагментации? Да, это более чем возможно. Однако, вопрос должен звучать: а приведет ли это к снижению производительности? И ответ - нет. Прежде всего, размер блока форматирования VMFS не имеет никакого отношения к вводу-выводу гостевой ОС. Скажем, у вас обычная ВМ с Windows и эта ВМ читает и пишет блоками по 8кБ на томе с 1МБ блоками. Гипервизор не будет читать блоками по 1 МБ, поскольку это вызовет серьезную деградацию общей производительности. Нет, гипервизор передаст СХД запрос гостевой ОС, и СХД в свою очередь будет действовать в соответствии с собственными настройками. Вероятно люди беспокоятся о том, что фрагментации повлияет на последовательные чтение / запись, но подумайте секунду-две. О каком последовательном вводе-выводе мы говорим, если смотреть со стороны СХД? Множество хостов, на каждом из которых не одна ВМ, обращающихся к целой куче виртуальных дисков, размазанных по один Ньютон знает какому количеству шпинделей. Последовательный ввод-вывод вдруг оказывается не таким уж последовательным, не так ли?
Оригинал: Duncan Epping (yellow-bricks.com)
суббота, 19 февраля 2011 г.
Виртуализация остановилась?
Scott Lowe нашел интересное мнение, опубликованное на InfoWorld.com. Цитирую (в моем переводе):
Правда ли она остановилась? Что же мешает предприятиям преодолеть рубеж в 18%? В комментариях к посту набралось достаточное количество интересных мнений, я их приведу:
Основная причина: Серверная виртуализация остановилась. Независимые исследователи и вендоры публикуют цифры, красноречиво говорящие, что хотя большинство крупных предприятий присматриваются к виртуализации, всерьез они ей так и не занялись.
Правда ли она остановилась? Что же мешает предприятиям преодолеть рубеж в 18%? В комментариях к посту набралось достаточное количество интересных мнений, я их приведу:
Влияние различных размеров блока VMFS
На одном из форумов VMTN написали о неожиданном влиянии единого размера блока для всех томов VMFS. Пользователь произвел обнуление неиспользуемого пространства, чтобы диски скомпрессировались при Storage vMotion. Сюрпризом стало то, что диски остались того-же самого размера и после Storage vMotion.
После нескольких тестов было обнаружено, что при Storage vMotion между массивами, или между датасторами с различными размерами блока VMFS диски компрессировались. Почему?
Ответ прост: в этом случае используется другой datamover (модуль перемещения данных). Поскольку вам это мало о чем говорит, объясню какие бывают datamover'ы:
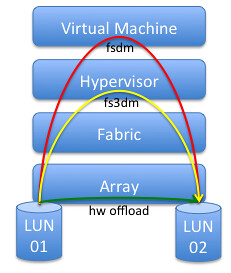
Так в чем же проблема? А проблема в одной маленькой строке текста в VAAI FAQ:
Как только выбирается датастор с другим размером блока, или датастор на другом массиве - гипервизор переключается на fsdm. Одно из немногих преимуществ этого datamover'а в том, что он "съедает" нули. В то время как fs3dm, вне зависимости от software / hardware offload, этого не делает и копирует блоки целиком.
Источник: Duncan Epping (yellow-bricks.com)
После нескольких тестов было обнаружено, что при Storage vMotion между массивами, или между датасторами с различными размерами блока VMFS диски компрессировались. Почему?
Ответ прост: в этом случае используется другой datamover (модуль перемещения данных). Поскольку вам это мало о чем говорит, объясню какие бывают datamover'ы:
- fsdm - самый старый datamover, с минимумом функций и самый медленный, поскольку данные проходят по всему стеку.
- fs3dm - был включен в состав vSphere 4.0 и содержал некоторые значительные изменения, позволяющие данным проходить не все уровни стека.
- fs3dm – hardware offload – datamover с поддержкой VAAI, аппаратной интеграции операций ввода/вывода с массивом. Появился в vSphere 4.1, имеет максимальную производительность и минимальные накладные расходы.
Так в чем же проблема? А проблема в одной маленькой строке текста в VAAI FAQ:
- The source and destination VMFS volumes have different block sizes
Как только выбирается датастор с другим размером блока, или датастор на другом массиве - гипервизор переключается на fsdm. Одно из немногих преимуществ этого datamover'а в том, что он "съедает" нули. В то время как fs3dm, вне зависимости от software / hardware offload, этого не делает и копирует блоки целиком.
Источник: Duncan Epping (yellow-bricks.com)
понедельник, 31 января 2011 г.
HA: перевыборы Primary Node
Как уже было написано ранее в "HA Deepdive: Primary nodes", при наступлении HA-события (умер хост) перевыборы Primary Node не происходят.
Часто спрашивают - почему так?
Ответ: перевыборы Primary Node происходят при введении хоста в Maintenance Mode или при отключении от кластера (перевод в состояние "Disconnected"). При наступлении же HA-события, хосту присваивается статус "Not Responding". И соотв. требует отключения хоста вручную, поскольку при "Not Responding" vCenter не может определить, что же именно произошло с хостом.
Часто спрашивают - почему так?
Ответ: перевыборы Primary Node происходят при введении хоста в Maintenance Mode или при отключении от кластера (перевод в состояние "Disconnected"). При наступлении же HA-события, хосту присваивается статус "Not Responding". И соотв. требует отключения хоста вручную, поскольку при "Not Responding" vCenter не может определить, что же именно произошло с хостом.
пятница, 14 января 2011 г.
Официальное объявление
Коллеги, прошу прощения за молчание в течении долгого времени. Блог не собирается закрываться, просто мне было чем заняться в конце прошлого года.
Рад объявить, что с начала 2011 года я стал сотрудником компании EMC на позиции vSpecialist, в одной команде с такими признанными гуру виртуализации как Alan Renouf, Jase McCarty, Simon Seagrave и др.
Надеюсь уже в ближайшем будущем порадовать вас "вкусными" материалами на русском языке :)
Ну и, разумеется, блог остается моим личным проектом для выражения моего личного мнения. Публикуемая информация может расходиться с официальной позицией компании EMC.
Рад объявить, что с начала 2011 года я стал сотрудником компании EMC на позиции vSpecialist, в одной команде с такими признанными гуру виртуализации как Alan Renouf, Jase McCarty, Simon Seagrave и др.
Надеюсь уже в ближайшем будущем порадовать вас "вкусными" материалами на русском языке :)
Ну и, разумеется, блог остается моим личным проектом для выражения моего личного мнения. Публикуемая информация может расходиться с официальной позицией компании EMC.
Подписаться на:
Сообщения (Atom)


