- Балансировка нагрузки в несбалансированном кластере
- Размещение ВМ при включении
Балансировка нагрузки
Прежде всего VMware DRS проверяет уровень загруженности кластера раз в 5 минут. Если обнаруживается несбалансированность, DRS попытается реорганизовать кластер при помощи VMotion и достичь состояния сбалансированности. Возникает вопрос: а как же отличить сбалансированный кластер от несбалансированного?
Взглянем на скриншот:
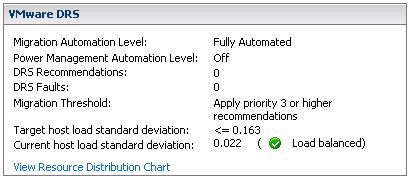
Мы видим три основных показателя
- Migration Threshold (порог миграции)
- Target host load standard deviation (целевое стандартное отклонение)
- Current host load standard deviation (текущее стандартное отклонение)
Помните, что при изменении "Migration Threshold" значение "Target host load standard deviation" тоже изменится. Иными словами, "Migration Threshold" указывает насколько несбалансированным может быть кластер. Также должна быть прямая зависимость между "Target host load standard deviation" и количеством хостов в кластере, однако мне не удалось найти прямых подтверждений в документации. На практике видно, что для кластера из двух хостов и пороге 3 THSLD равно 0.2, а для трех хостов - 0.163. Каждые пять минут DRS вычисляет уровень потребления ресурсов на каждом хосте и делит это число на мощность хоста:
Результаты всех хостов будут использованы для вычисления среднего и стандартного отклонения (“Current host load standard deviation”). Если среда не сбалансированная и текущее отклонение превышает пороговое значение (“Target host load standard deviation”) DRS выдаст рекомендации либо самостоятельно начнет миграцию виртуальных машин.sum(expected VM loads) / (capacity of host)
Остается вопрос - а как DRS решает, какую/какие ВМ нужно мигрировать?
Для определения используются следующая процедура:
While (load imbalance metric > threshold) {
move = GetBestMove();
If no good migration is found:
stop;
Else:
Add move to the list of recommendations;
Update cluster to the state after the move is added;
}Пока кластер несбалансирован (Current host load standard deviation > Target host load standard deviation) нужно выбрать ВМ для миграции по определенному критерию, симулировать ее миграцию, перерассчитать "Current host load standard deviation" и добавить миграцию в список рекомендаций. Если кластер все еще не сбалансирован, то повторить процедуру.
Так как же выбирается лучшая ВМ для миграции? DRS использует следующую процедуру:
GetBestMove() {
For each VM v:
For each host h that is not Source Host:
If h is lightly loaded compared to Source Host:
If Cost Benefit and Risk Analysis accepted
simulate move v to h
measure new cluster-wide load imbalance metric as g
Return move v that gives least cluster-wide imbalance g.
}Для каждой ВМ проверить, будет ли кластер более сбалансированным в результате миграции ВМ на все хосты, менее загруженные, чем текущий, а так же отвечает ли миграция критериям "Cost Benefit" (стоимость и эффективность) и "Risk Analysis" (анализ рисков). Сравнить результат каждой комбинации ВМ<->хост и вернуть миграцию, в результате которой кластер будет наиболее сбалансирован.В итоге мы должны получить миграцию, которая даст наибольший эффект в отношении сбалансированности кластера. По этой причине чаще всего выбираются большие ВМ, поскольку после их миграции сильнее всего меняется текущее отклонение. Если же этой миграции не достаточно, чтобы текущее отклонение убралось в границы целевого, то снова исполняется процедура "GetBestMove". В конечном итоге мы получаем список рекомендуемых миграций.
Теперь вопрос: а что входит в критерии "Cost Benefit" и "Risk Analysis", и зачем они вообще нужны?
Прежде всего мы хотим избежать постоянных миграций, и делаем это путем сравнения затрат, эффекта и и рисков.
Cost benefit
Risk Analysis
- Затрата: Резерв CPU на время миграции на целевом хосте
- Затрата: Использованная теневой машиной во время миграции память на целевом хосте
- Затрата: "Downtime" ВМ во время миграции
- Эффект: Больше доступных ресурсов на хосте-источнике после миграции
- Эффект: Больше ресурсов для ВМ, поскольку она перемещается на менее загруженный хост
- Эффект: Баланс кластера
- Стабильная или нестабильная загрузка ВМ (исторические данные)
Основываясь на этих соображениях вычисляется метрика цена-эффект-риск, и если она имеет приемлемое значение, то миграция ВМ считается целесообразной.
Каждая рекомендация к миграции получает приоритет, основанный на текущем отклонении (Current host load standard deviation). Алгоритм вычисления описан в данной статье KB. Пришлось прочитать ее 134 раза, пока я не понял, что именно они хотели объяснить. Я использую информацию со скриншота, чтобы пояснить это вам. Уточню, что LoadImbalanceMetric - это текущее отклонение, а ceil по сути округление вверх.
В итоге для рекомендации будет выдан приоритет 5, если кластер несбалансирован.6 - ceil(LoadImbalanceMetric / 0.1 * sqrt(NumberOfHostsInCluster)) 6 - ceil(0.022 / 0.1 * sqrt(3))
Размещение ВМ
Как вы знаете, первичное размещение ВМ при включении также является частью DRS. Для этого DRS анализирует кластер по алгоритму, описанному в "Балансировке нагрузки", но как же считать тогда ресурсы включаемой ВМ? А вот здесь как раз собака порылась, DRS предполагает, что загрузка ресурсов для данной ВМ составит 100%, причем лимиты и резервы не принимаются во внимание. Так же, как и HA, DRS имеет свой "Admission control" (контроль ресурсов). Если DRS не может гарантировать 100% доступность ресурсов для данной машины, то уже включенные машины будут мигрированы с выбранного хоста, чтобы включить новую. Однако, если ресурсов будет недостаточно даже при условии миграции, то машина не включится.
Оригинал: Duncan Epping



Комментариев нет:
Отправить комментарий