Значит ли это, что вы не должны создавать больших ВМ? Нет, если ВМ действительно требует большой вычислительной мощности. Причина, по которой я пишу это - большинство IT отделов руководствуются одной и той же политикой и для физических и для виртуальных машин. ВМ дают множество процессоров и кучу памяти на случай если вдруг это когда-либо потребуется в будущем. И хотя этот подход экономит время и позволяет не ввзяываться в офисную политику, для больших ВМ он может вылиться в ненужные задержки. И вот почему:
Узел NUMA
Большинство современных процессоров, таких как новенькие Intel Nehalem и закаленные в боях AMD Opteron, являются представителями архитектуры NUMA (Non-Uniform Memory Access). У каждого процессора есть своя собственная "локальная" память, а процессор и память вместе объединяются в узел NUMA. ОС будет пытаться использовать локальную память процессора, но при необходимости может обращаться и к "удаленной" памяти, принадлежащей другому NUMA узлу. Время доступа к памяти может варьироваться, в зависимости от расположения памяти относительно процессора, потому что обращение к собственной локальной памяти происходит быстрее, чем к удаленной.

Рисунок 1: Доступ к локальной и удаленной памяти
При обращении к удаленной памяти увеличивается задержка, соотв. нужно избегать этого до последнего. Но как можно гарантировать, что большинство обращений будут локальными?
Западня номер 1 при сайзинге ВМ: сайзинг vCPU и первичное размещение
ESX является NUMA aware, т.е. знает, что работает на NUMA системе, и соотв. будет применять специализированный NUMA планировщик CPU. На обычных, не-NUMA системах, планировщик ESX разпределяет нагрузку между всеми сокетами в режиме "round-robin". Этот подход ведет к увеличению производительности, поскольку задействуется максимальный объем кэша. Каждый процессор vSMP машины при этом размещается на следующем сокете.
Но на NUMA системе включается в работу совершенно иной планировщик, использующий оптимизацию под NUMA систему - а именно размещение ВМ целиком на одном NUMA узле, и виртуальные процессоры и память. Это гарантирует нам максимально возможную "локальность" памяти.
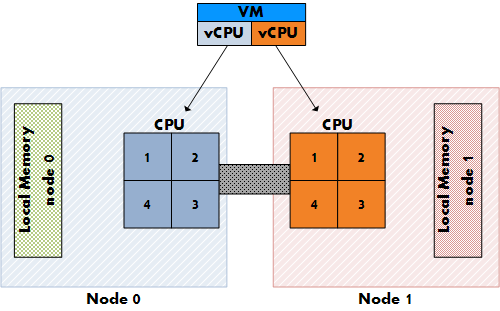
Рисунок 2: Размещение vCPU на не-NUMA системе
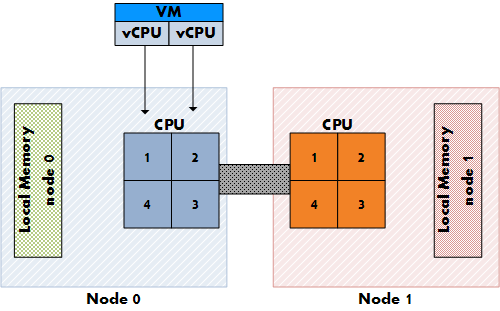
Рисунок 3: Размещение vCPU на NUMA системе
В настоящий момент AMD и Intel предлагают 4-ядерные процессоры, но если пользователь захочет создать 8-процессорную ВМ? Если ВМ не умещается внутри одного NUMA узла, то vCPU распределются традиционным образом, по всей системе. ВМ не получит ничего от оптимизации доступа к памяти, и соотв. при доступе процесса к удаленной памяти будет появляться дополнительная задержка.
Западня номер 2: сайзинг памяти ВМ и размер локальной памяти
Отлично, все vCPU поместились в один узел NUMA, но если у ВМ памяти больше, чем локальной памяти узла? Неправильная конфигурация размера памяти ВМ приведет к тому, что планировщик не сможет использовать оптимизацию для это ВМ, и ее память будет разбросана по всему серверу.
Так как же можно узнать, сколько памяти установлено на каждом NUMA узле? Обычно для каждого процессора (сокета) устанавливают одинаковое количество памяти, и соотв. доступная физическая память (минус память сервис-консоли) делится между сокетами. Например, по 16GB памяти на каждый сокет для двухпроцессорной (2-сокетной) системы с 32GB памяти. Быстрый способ уточнить конфигурацию памяти в NUMA системе - esxtop. Esxtop будет показывать статистику NUMA только при работе на NUMA системе. Первое число указывает на объем памяти, управляемый ESX на данном NUMA узле, а в круглых скобках мы видим объем свободной памяти на данном узле.

Рисунок 4: общая статистика памяти в esxtop
Давайте поисследуем немного NUMA статистику esxtop. Данная система - HP BL460c с двумя 4-ядерными процессорами Nehalem и 64GB памяти. Как видно, у каждого NUMA узла примерно по 32GB. На первом узле свободно 13GB, а на втором всего 372MB - видимо память скоро совсем закончится, но, к счастью, ВМ на этом узле все же могут обращаться к удаленной памяти. Когда у ВМ определенная часть памяти становится удаленной, планировщик перемещает ВМ на другой узел, чтобы увеличить степень локальности памяти. Нигде в документации не указано, какая именно степень локальности требуется, чтобы началась миграция, но плохой локальностью считается ситуация, когда 80% памяти ВМ размещено в локальной памяти. Поэтому было бы разумно предположить, что миграция произойдет при падении локальности ниже 80%. Esxtop может показать NUMA статистику памяти для каждой ВМ: запустите esxtop, нажмите m для статистики памяти, затем f для изменения отображаемой статистики, и еще раз f для выбора статистики NUMA.
Рисунок 5: Изменяем статистику
На рисунке 6 можно увидеть NUMA статистику для уже упомянутого ESX сервервера с полностью загруженным NUMA узлом. Поле N%L показывает процент памяти, размещенной локально (локальность памяти) для ВМ.
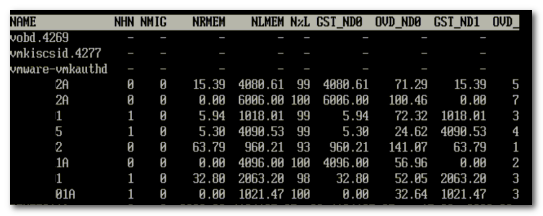
Рисунок 6: Статистика NUMA
Как мы видим, немногие машины работают с удаленной памятью. Man страница для esxtop поясняет значение всех параметров:
| Metric | Explanation |
|---|---|
| NHN | Current Home Node for virtual machine |
| NMIG | Number of NUMA migrations between two snapshots. It includes balance migration, inter-mode VM swaps performed for locality balancing and load balancing |
| NRMEM (MB) | Current amount of remote memory being accessed by VM |
| NLMEM (MB) | Current amount of local memory being accessed by VM |
| N%L | Current percentage memory being accessed by VM that is local |
| GST_NDx (MB) | The guest memory being allocated for VM on NUMA node x. “x” is the node number |
| OVD_NDx (MB) | The VMM overhead memory being allocated for VM on NUMA node x |
Transparent page sharing and локальность памяти.
Так что будет с transparent page sharing (TPS)? Ведь работа TPS может увеличить задержку, если ВМ с узла 0 будет разделять страницу памяти с ВМ с узла 1. К счастью, инженеры VMware подумали об этом, и по умолчанию TPS между узлами отключена с целью повышения локальности памяти. TPS все еще работает, но будет разделять доступ к страницам памяти только внутри узла. Задержки при доступе к удаленной памяти перевешивают положительный эффект экономии памяти на уровне всей системы.
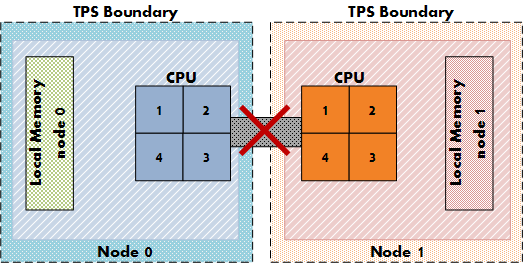
Figure 7: NUMA TPS boundaries
Данное поведение можно изменить через параметр VMkernel.Boot.sharePerNode. Но как и большинство параметров по умолчанию в ESX, этот параметр стоит изменять только если вы абсолютно уверены, что для вашей среды это принесет преимущества. В 99,99% сред наилучший вариант - оставить настройку по умолчанию.
Оригинал: Frank Denneman



Комментариев нет:
Отправить комментарий