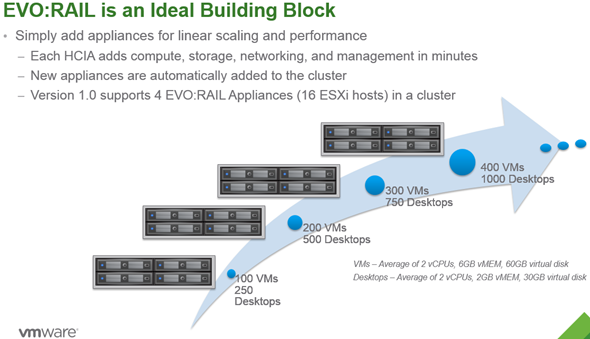
Это не новая тема, я её уже освещал на VMworld 2013 на сессии STO5420. Хранилища (такие штуки которые хранят информацию, и делают разные вещи с информацией) можно разделить на 4 группы. Главное здесь не зациклиться на не основных вещах.
Люди мысленно разделяют хранилища по их физическим свойствам типа интерконнекта (они все используют Infiniband!), протоколу (блочная СХД! Или NFS! Или мультипрокольная!) или даже аппаратное это или только программное решение (это просто софт на сервере!).
Это все не правильная таксономия и неправильный способ группировки! Программная архитектура - вот главный принцип группировки, так как именно по нему определяются фундаментальные характеристики. Все остальные элементы - частности реализации архитектуры.
Поймите меня правильно - они важны, но не фундаментальны.
Тип 1. Кластеризованная архитектура (вертикально масштабируемые решения)
Такие решения характеризуются тем, что в них не используется общая память между контроллерами, и, по сути, данные находятся в кэше одного контроллера. СХД может быть A/A (оба контроллера активны), A/P (один контроллер пассивен), A/S (каждый контроллер обрабатывает свой объём данных, то есть у контроллеров ассиметричный доступ к данным).
Обработка данных такими СХД выглядит так:
Плюсы:
- Задержка между контроллерами минимальна. Практически нулевая.
- Скорость работы массива зависит от дисков.
- Так как задержки в таких решениях минимальны, то СХД идеальны для транзакционной модели доступа к данным.
- Простая архитектура и минимальные коммуникации между контроллерами делают архитектуру очень легко расширяемой функционально (компрессия, дедупликация, тиринг).
- Легко поддерживать, управлять, настраивать.
Минусы:
- Масштабируемость ограничена мощностью контроллера или парой. Обычно до 1000 дисков.
- Доступность данных гарантируется переключением между контроллерами. Что может привести к понижению производительности при выходе одного из строя.
Точки отказа:
- Сам контроллер и его компоненты - железо и ПО.
- Диски, порты в фабрике и т.д.
Примеры:
- Active/Standby- Nimble, Pure Storage, Tintri, UCS Whiptail
- Active/Passive- NetApp, EMC VNX*
- Active/Active- HDS HUS, Dell Compellent, EMC VNX*, IBM V7000
Сюда же попадает все PCIe решения типа Fusion-IO или EMC XtremCache только без отказоустойчивости. Если это решение использует специализированное ПО для обеспечения отказоустойчивости, распределённого хранилища данных, целостности данных - смотрите на ПО, оно попадает под одну из четырёх архитектур.
Поверх такого можно поставить федеративное решение, чтобы сделать их более горизонтально масштабируемыми с точки зрения управления. Однако IO будет балансироваться ровно до попадания данных на контроллер. Такие решения также могут использоваться для балансировки между контроллерами и пулами (VDM Mobility у VNX и Clustered ONTAP у NetApp). Как по мне, такое решение можно с натяжкой назвать горизонтально масштабируемым. Так как данные, так или иначе, находятся за одним или другим контроллером. Балансировка и тюнинг важны, в отличие от архитектур 2 и 3, где она просто есть.
Тип 2. Слабо связанные (горизонтально масштабируемые решения)
Архитектурно звучит как самое простое решение, хотя на самом деле, это самое сложное решение. Такое решение тоже не использует общую память между нодами, но сами данные распределены по множеству нод. Также такому решению характерно большое количество коммуникаций между нодами при записи данных (дорогая операция с точки зрения задержек). Но они всё равно транзакционны - записи хоть и распределены, но все консистентны.
Заметьте на картинке нода обозначена без отказоустойчивости, считается что устойчивость гарантируется распределённостью и копиями данных.
Обычно задержки в таких массивах прячут за хранилищем с низкой латентностью (NVRAM, SSD и т.д.), но в любом случае всегда больше задач по балансировке и копирования данных чем в обычном кластере типа 1 так как операции записи распределённые.
Иногда выделяется группа нод, хранящая только метаданные об остальных нодах. Логика сходна с федерацией в предыдущей архитектуре.
Преимущество такой архитектуры в простоте масштабирования и управления. Горизонтальное масштабируемые системы просто идеальны для транзакционных нагрузок так как из-за распределённой природы таких систем можно использовать не отказоустойчивые сервера не связанные между собой, с чем отлично справится старый добрый Ethernet.
Несмотря на то, что способы интерконнекта могут отличаться (Ethernet, Infiniband и тд), для всех таких решений критичным местом является сеть для распределённой записи данных. Подтверждение о записи будет отправлено инициатору только после успешной записи данных на нескольких разных нодах. Это, в свою очередь, приводит к увеличению зоны отказа. Эти два параметра являются основными ограничивающими масштаб факторами.
Обработка запроса на запись выглядит следующим образом:
И, соответственно, на чтение:
Плюсы:
- В конвергентных решения задержки на запись практически нулевые от клиента к массиву. Основные задержки вызывает копирование между нодами
- Быстрый локальный кэш для минимизации задержек синхронизации
- Производительность масштабируется практически линейно
- Отличная производительность при последовательном чтении
- Практически не используются специализированные аппаратные решения
- Обычно используются большие пулы ресурсов, что облегчает администрирование
Минусы:
- Больше нод - больше ресурсов на координацию
- В случае выхода какого-либо компонента из строя сбойной помечается вся нода
- Компромисс между производительностью и требованием к объёму данных. Некоторые решения разбивают данные на блоки с хэшами или контрольными суммами, что уменьшает скорость случайного доступа и требование к пространству или используют несколько копий данных, увеличивая требования к пространству
- Создание дискового пула является сложной фоновой задачей съедающей ресурсы
- Некоторые приложения не могут использовать все преимущества такой архитектуры, что приводит к локальной высокой нагрузке.
Точки отказа:
- Все отказы на ноде приводят к полному её отказу.
- Некоторые решения используют локальные RAID массивы, что приводит к тому что выход локального диска не приведёт к вывод из строя всей ноды.
Примеры:
- Аппартные решения: EMC Isilon, Dell Equallogic, HP StoreVirtual 4000
- Программные решения: VMware VSAN, IBM SONAS, HP StoreVirtual VSA, EMC ScaleIO, VMware Virsto
- Конвергентные решения: SimpliVity, Nutanix.
Тип 3. Связанные, горизонтально масштабируемые архитектуры
Архитектура, в которой используется общая память между контроллерами (кэш или метаданные), а сами данные разнесены по разным нодам. Огромное количество коммуникаций между контроллерами по любому типу операций.
Общая память является критичным моментом для данной архитектуры. Изначально это позволяло

получить симметричный доступ к данным через любой контроллер. Разрабатывалась так, чтобы при выходе из строя любого элемента (запланированном или нет) операции ввода-вывода оставались относительно сбалансированными.
Несмотря на то, что схема данной архитектуры очень похожа на предыдущую, разница в том что модель распределённого и общего доступа к метаданным означает что такие решения не просто используют Infiniband, а зависят от RDMA для обеспечения общего доступа к метаданным между нодами.
Возьмём к примеру два решения от EMC - Isilon и XtremeIO. Не смотря на то что они оба очень похожи - оба решения горизонтально масштабируемы и оба используют Infiniband для интерконнекта разница в том, что Isilon использует Infiniband для минимизации задержек между нодами, и не использует общей памяти между нодами. Фактически, Isilon может использовать Ethernet (так и есть в VA версии), а XtremeIO зависим от RDMA.
Еще один важный момент отличия между двумя архитектурами: чем больше связанны контроллеры между собой, тем меньше, и предсказуемо меньше, будут задержки, но меньше масштабируемость из-за роста сложности системы.
Операции ввода-вывода выглядят так:
Плюсы:
- Задержки между контроллерами практически нулевые
- Задержки записи данных зависят в основном от физических дисков
- Идеально подходят для высоконагруженных систем
- Ограничением масштабируемость гарантируется производительность
Минусы:
- Масштабируемость ограничена максимальным количеством контроллеров
- Хотя некоторые системы и используют x86 архитектуру, для них используется собственное аппаратное обеспечение. В остальных случаях используются ASIC. Оба этих фактора приводят к более долгому переходу на новые технологии.
Точки отказа:
- Архитектура разработана с учётом отсутствия или отказоустойчивости любого элемента.
Примеры:
- EMC Symmetrix VMAX
- HDS VSP
- HP 3Par
Тип 4. Распределённая архитектура без общих элементов (shared nothing)
В распределённых системах не используется общая память, данные разнесены по разным нодам, но не транзакционно, а "лениво". То есть данные записываются на одну ноду, и с определённой периодичностью (иногда) копируются на другие ноды для обеспечения защищённости. Системы данного типа не транзакционны.
Неизбежный интерконнет всегда построен на Ethernet (просто потому что дёшево и всегда доступно), ноды не отказоустойчивы. Корректность данных не всегда обеспечивается СХД, а программным стеком выше с помощью контрольных сумм.
Эта простота делает данную архитектуру самой масштабируемой из всех. У неё абсолютно никакой зависимости от аппаратного обеспечения, и практически всегда выполнена в программном виде. Масштабируется до петабайт с такой же лёгкостью как другие СХД до терабайт. Обычно используется объектные и non-POSIX файловые системы часто даже лежащие поверх локальных ФС, используемых для базовых задач.
Примеры:
- HDFS
- EMC Atmos
- Блочный доступ в EMC ViPR
- Amazon AWS S3 (хотя никто за пределами Amazon не знает как на самом деле обстоит дело, я склоняюсь к типу 3)
- Ceph
- Openstack Swift
Оригинал:
virtualgeek.typepad.com
Оригинал:
vmtyler.com