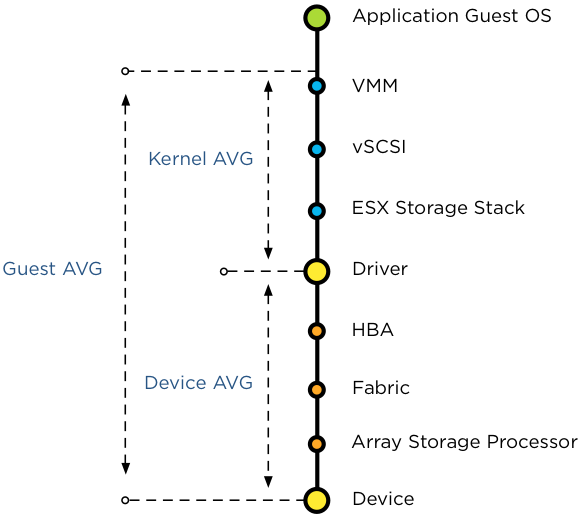
| iSCSI | NFS | FC | FCoE |
| Описание | Протокол блочного уровня.
Все SCSI команды инкапсулируются в TCP/IP пакеты и передаются на СХД | Протокол файлового уровня.
NFS массив предоставляет доступ ESX хосту к своей локальной файловой системе.
ESX хост же обращается к метаданным и файлам используя протокол основанный на RPC.
В данный момент поддерживается NFS v3 поверх TCP/IP | Протокол блочного уровня.
Все SCSI команды инкапсулируются в FC фреймы | Протокол блочного уровня.
Все SCSI команды инкапсулируются в Ethernet фреймы.
Во многом схож с Fibre Channel.
Поддерживается с vSphere 5 |
| Возможности реализации | 1. vSphere vmkernel (обычная сетевая карта)
2. Dependent iSCSI Initiator (сетевая карта с функциями SCSI Offload+vmkernel)
3. Independent iSCSI Initiator (отдельный HBA адаптер) | vSphere vmkernel (обычная сетевая карта) | Выделенный HBA адаптер.
Для отказоустойчивости и поддержки multipathing требуется минимум 2 адаптера | 1. Hardware Converged Network Adapter (CNA)
2. Software FCoE инициатор (требуется сетевая карта с поддержкой FCoE) |
| Производительность | 1. Поддерживается 1Gbit\10Gbit Ethernet.
2. Несколько соединений могут быть объединены в одну сессию.
3. Поддержка Jumbo Frames.
4. Более высокая нагрузка на ЦПУ за счёт инкапсуляции трафика | 1. Поддерживается 1Gbit\10Gbit Ethernet.
2. Не смотря на возможность использования UDP, VMware её не поддерживает.
3. Поддержка Jumbo Frames.
4. Более высокая нагрузка на ЦПУ за счёт инкапсуляции трафика | 1. Поддерживается 1/2/4/8 и 16Gb HBA, но последние в vSphere 5 должны работать в режиме 8Gb.
2. Buffer-to-Buffer и End-to-End кредиты гарантируют сеть без потери пакетов.
3. Низкая нагрузка на ЦПУ, так как HBA инкапсулирует весь трафик | 1. Требует 10Gb Ethernet.
2. Требует поддержки Jumbo Frames (стандартный размер пакета FC – 2.2KB, а не 1.5 как у Ethernet).
3. Меньшая нагрузка на сеть, по сравнению с iSCSI и NFS, так как нету инкапсуляции SCSI в TCP\IP |
| Балансировка нагрузки | VMware Pluggable Storage Architecture (PSA)поддерживает Round-Robin для распределения нагрузки между путями.
Лучше использовать с большим количеством LUN | В данный момент такой возможности не существует, так как используется только одна сессия.
Агрегация каналов может быть достигнута путём подключения по разным путям | VMware Pluggable Storage Architecture (PSA)поддерживает Round-Robin для распределения нагрузки между путями.
Лучше использовать с большим количеством LUN | VMware Pluggable Storage Architecture (PSA)поддерживает Round-Robin для распределения нагрузки между путями.
Лучше использовать с большим количеством LUN |
| Отказоустойчивость | Отказоустойчивость обеспечивается с помощью Storage Array Type Plugin (SATP) для всех поддерживаемых iSCSI массивов | NIC Teaming. Хотя данный метод не защищает от сбоев на стороне хранилища | Отказоустойчивость обеспечивается с помощью Storage Array Type Plugin (SATP) для всех поддерживаемых FC массивов | Отказоустойчивость обеспечивается с помощью Storage Array Type Plugin (SATP) для всех поддерживаемых FCoE массивов |
| Проверка на наличие ошибок | Протокол использует TCP, который пересылает пакеты в случае потери пакетов | Протокол использует TCP, который пересылает пакеты в случае потери пакетов | FC является сетью с гарантией сохранности данных.
Обеспечивается благодаря Buffer-to-Buffer и End-to-End кредитам и регулированием полосы пропускания в случае нехватки ресурсов | FCoE требует использования сети с гарантией сохранности данных.
Достигается использованием механизма Pause Frame в случае нехватки ресурсов |
| Безопасность | Авторизация, в том числе и двусторонняя, обеспечивается протоколом Challenge Handshake Authentication Protocol (CHAP).
Рекомендуется использовать VLAN или выделенные сети для разделения трафика | Рекомендуется использовать VLAN или выделенные сети для разделения трафика | Некоторые свитчи поддерживают VSAN, являющуюся аналогом VLAN.
Также рекомендуется использовать зонинг между массивов и хостами | Некоторые свитчи поддерживают VSAN, являющуюся аналогом VLAN.
Также рекомендуется использовать зонинг между массивов и хостами |
| Поддержка Virtual API for Array Integration | Поддержка определённых примитивов зависит от производителя. Всего доступны следующие примитивы: Atomic Test/Set, Full Copy, Block Zero, Thin Provisioning, Unmap.
Все они интегрированы в ESXi и не требуют установки дополнительных элементов | Поддержка определённых примитивов зависит от производителя. Всего доступны следующие примитивы:Full Copy (не поддерживается для Storage vMotion, только для холодной миграции), Write Zeros, Clone Offload.
Требуется плагин для ESXi от производителя массива | Поддержка определённых примитивов зависит от производителя. Всего доступны следующие примитивы: Atomic Test/Set, Full Copy, Block Zero, Thin Provisioning, Unmap. Все они интегрированы в ESXi и не требуют установки дополнительных элементов | Поддержка определённых примитивов зависит от производителя. Всего доступны следующие примитивы: Atomic Test/Set, Full Copy, Block Zero, Thin Provisioning, Unmap. Все они интегрированы в ESXi и не требуют установки дополнительных элементов |
| Загрузка ESXi с СХД | Да | Нет | Да | Да для CNA, нет для software initiator |
| Поддержка Raw Device Mapping | Да | Нет | Да | Да |
| Максимальный размер datastore | 64ТБ | Зависит от производителя массива | 64ТБ | 64ТБ |
| Максимальное количество устройств | 256 | по умолчанию 8, максимально 256 | 256 | 256 |
| Прямое подключение СХД в ВМ | Да, с помощью инициатора в ВМ | Да, с помощью клиента в ВМ | Нет, но FC устройства могут быть подключены к ВМ с помощью NPIV. Требует предварительного подключения RDM и поддержки NPIV со стороны оборудования | Нет |
| Поддержка Storage vMotion | Да | Да | Да | Да |
| Поддержка Storage DRS | Да | Да | Да | Да |
| Поддержка Storage I/O Control | Да, с vSphere 4.1 | Да, с vSphere 5.0 | Да, с vSphere 4.1 | Да, с vSphere 5.0 |
| Поддержка MSCS в ВМ | VMware не поддерживает такую конфигурацию, если ВМ хранятся на iSCSI массиве. Если iSCSI LUN подключён напрямую в ВМ, то такая конфигурация поддерживается Microsoft. | Нет | Да | Нет |
| Сложность настройки | Средняя. Необходимо знать FQDN или IP адрес массива. Может быть необходима настройка подключений инициатора со стороны массива. Сразу после обнаружения LUN доступен для форматирования под VMFS или подключения как RDM | Низкая. Необходимо знать FQDN или IP адрес массива и точка монтирования. Сразу после обнаружения массив доступен для работы | Высокая. Включает в себя зонирование со стороны свитча и маскирование LUN со стороны хоста. Сразу после обнаружения LUN доступен для форматирования под VMFS или подключения как RDM | Высокая. Включает в себя зонирование со стороны свитча и маскирование LUN со стороны хоста. Сразу после обнаружения LUN доступен для форматирования под VMFS или подключения как RDM |
| Преимущества | Не требует использования дополнительного оборудования, можно построить используя существующие ресурсы. Хорошо известный и зрелый протокол. Администраторы с небольшими знаниями о сетях смогут без проблем подключить массив. Проблемы решаются использованием стандартных инструментов типа Wireshark | Не требует использования дополнительного оборудования, можно построить используя существующие ресурсы. Хорошо известный и зрелый протокол. Администраторы с небольшими знаниями о сетях смогут без проблем подключить массив. Проблемы решаются использованием стандартных инструментов типа Wireshark | Хорошо известный и зрелый протокол. Используется в большинстве критически важных инфраструктур | Позволяет строить конвергированные сети, консолидируя трафик разных в одной сети, используя CNA. Благодаря использованию протокола DCB (Data Center Bridging ) FCoE является протоколом без потери пакетов не смотря на то, что работает поверх Ethernet. |
| Недостатки | Невозможность маршрутизации при использовании iSCSI Binding.
Возможны проблемы с безопасностью из-за отсутствия встроенных механизмов шифрования, необходимость использовать VLAN.
Software iSCSI инициатор повышает нагрузку на ЦПУ.
TCP повышает задержки | Так как используется только одна сессия на подключение, настройка при использовании multipathing требует аккуратности и внимания. Нету PSA multipathing. Возможны проблемы с безопасностью из-за отсутствия встроенных механизмов шифрования, необходимость использовать VLAN.
VMware все еще использует NFS v3, хотя доступны v4 и v4.1.
NFS повышает нагрузку на ЦПУ.
TCP повышает задержки | Не поддерживается FC 16Gb. Необходимо дополнительное оборудование - свитчи, HBA и т.д. Сложность в поддержке.
Сложность в решении проблем. | Новый протокол, и не такой зрелый, как остальные.
Требует lossless 10Gb Ethernet.
Для маршрутизации используются не механизмы IP, а свой протокол - FIP (FCoE Initialization Protocol). Возможны сложности в решении проблемы из-за использования одного канала для всех видов трафика |