Итак, с основными параметрами жёстких дисков мы уже разобрались. Второй этап – выбор типа RAID массива. Рассмотрим основные типы RAID массивов, их плюсы и минусы, а также вопрос о производительности наиболее часто используемых типов RAID, и их накладных расходах на запись.
Основные типы RAID массивов, их плюсы и минусы

RAID0 (чередование) - данные разбиваются на блоки, которые пишутся на все диски по очереди. Требует минимум 2 диска. Плюс - в скорости, так как он растёт линейно с ростом количества дисков. Объём равен сумме объёма дисков. Минус - отсутствие резервирования, и выход 1 диска из строя означает потерю данных. Вывод: не рекомендовано к использованию в чистом виде.

RAID1 (зеркалирование) - данные пишутся на все диски зеркально. Требует минимум 2 диска. Плюс - скорость чтения растёт с добавлением количества дисков. Работоспособен, пока есть хоть 1 диск в группе. Минусы: накладные расходы составляют 2 к 1 (вопрос накладных расходов я раскрою ниже). Итоговый объём равен объёму одного диска. Вывод: самый простой способ организации избыточности.

RAID5 (чередование данных с использованием контрольных сумм) - каждый следующий блок данных пишется на следующий диск, то есть по сути это RAID0, но для чётности данных используются контрольные суммы. Объём массива равен сумме объёма дисков минус объём самого маленького из них (используется для этих самых контрольных сумм). Требует минимум 3 диска. Плюсы: итоговый объём массива, распараллеливание чтения по всем дискам. Минусы: низкая скорость записи при случайно доступе, в случае выхода из строя одного из дисков массив переходит в режим деградации и начинает пересборку. Это приводит к падению производительности, а в случае выхода из строя еще одного диска - потерей данных. Время пересборки массива, учитывая объёмы современных дисков, может достигать нескольких дней. Надёжность дисков в массиве очень быстро и сильно снижается. Высокие накладные расходы

RAID6 (чередование данных с использованием двух контрольных сумм) - тоже самое, что и RAID5, только используются две разных контрольных суммы. Требует минимум 4 диска. Плюсы: способен выдержать выход из строя двух дисков. Минусы: еще медленнее, чем RAID5, а накладные расходы еще выше.
RAID10 (сочетание зеркалирования с чередованием) - Требует минимум 4 диска. Технически есть два типа RAID10 - RAID 0+1 (два RAID0 объединяют в зеркало) и RAID 1+0 (два зеркала объединяют в RAID0). Представим, что у нас есть 8 дисков и нам их нужно собрать в RAID. Если мы создадим RAID1+0, то получим 4 группы зеркальных дисков, на которые данные будут писаться как на RAID0. В случае с RAID0+1 мы получим 2 группы RAID0 по 4 дисков в каждой, данные на которые будут писаться зеркально.
Плюсы: чтение распараллеливается по всем дискам в массиве. Самый высокий уровень отказоустойчивости.
Минусы: у RAID0+1 низкая отказоустойчивость, так как у нас 2 RAID0 массива, который сам по себе не безопасен, и если из строя выйдет хотя бы 1 диск в массиве, то контроллер будет работать только со вторым RAID0 массивом. В случае же RAID1+0 если из строя выйдет 1 диск, то это повлияет только на его партнёра, но никак не весь массив в целом. В случае пересборки RAID10 общая производительность СХД не понизится. Итоговый объём данных равен половине объёма дисков.
В обзор не вошли RAID2 (побитовое чередование с контрольными суммами. Под суммы нужно n-1 дисков), RAID3 (побайтовое чередование с контрольными суммами. В отличие от RAID2 менее избыточен и не исправляет ошибки на лету), RAID4 (поблоковый RAID3). Основное отличие RAID3 и RAID4 от RAID5 в том, что для хранения контрольных сумм используется выделенный диск, в то время как RAID5 контрольные суммы размазывает по всем дискам в массиве.
И последнее: есть еще не очень широко применяющиеся уровни RAID - RAID50 и RAID60.Так же, как и в случае RAID10 это сочетание RAID5(6) с RAID0.
Накладные расходы у RAID5 и RAID10
То что скорость чтения отличается от скорости записи у RAID массивов отличается - это очевидный факт. С чтением всё просто - оно происходит со всех дисков сразу. С записью немного по другому: у RAID10 эффективная запись происходит только на половину дисков массива (вторая половина массива пишет то же самое, поэтому распараллелить запись можно на двое меньшее количество дисков), и в итоге накладные расходы составляют 2 к 1 (2 IO для 1 записи), и они не меняются ни в каком случае. У RAID5 же производительность меняется в зависимости от количества и последовательности данных. Допустим вам надо перезаписать один единственный блок. Для этого контроллеру надо прочитать блок данных и его контрольную сумму, потом рассчитать новую, и записать блок данных и его контрольную сумму. В итоге мы имеем пропорцию 4 к 1. То есть 4 IO для 1 записи.
Всё становится еще хуже, если необходимо перезаписать часть блока данных. В таком случае контроллеру нужно прочитать весь блок данных, за исключением перезаписываемых, посчитать контрольную сумму и записать, в итоге, данные и новую контрольную сумму. В итоге накладные расходы в этом случае посчитать немного сложнее: если считать D за общее количество дисков в массиве, C как количество изменяемых блоков, то Т – общее количество IOPS равно:
Т = ((D-C) + 1 чтение контрольной суммы) + (C+1 запись контрольной суммы))
Но соотношение про 4 к 1 у RAID5 чисто теоретическое. На практике всё выглядит немного иначе. Допустим, у вас есть RAID5 состоящий из 9 дисков (8 с данными и 1 один с контрольными суммами). Контроллеру необходимо перезаписать 2 два сегмента в блоках данных. В таком случае формула будет выглядеть следующим образом: 8-2+1 = 7 IO чтения, после чего 2+1 = 3 IO записи. В итоге, для изменения 2 блоков данных контроллеру необходимо обработать 10 IO, а накладные расходы составят уже не 1 к 4, а 1 к 5.
Но, представим себе второй вариант: всё тот же RAID5 из девяти дисков, но изменить нужно уже 6 сегментов в блоках данных. И тогда всё меняется: 8-6+1=3 IO чтения, и 6+1=7 IO записи. В итоге для обработки 6 блоков данных контроллеру нужно обработать 10 IO, а накладные расходы составят уже 1 к 1.66.
А для полной перезаписи 8 блоков данных в данном случае понадобилось бы всего 9 IO, а накладные расходы составят 1 к 1.125.
В итоге, максимум производительности от RAID5 вы получите только, когда контроллер будет перезаписывать весь блок данных, чтобы задействовать мощности всех дисков массива. Некоторые компании, например ЕМС, стараются держать записываемые блоки в кэше, и перезаписывать данные в массиве, только когда контроллер сможет перезаписать весь блок данных.
В итоге: при случайной записи у RAID10 накладные расходы статичны – 1 к 2, а у RAID5 - 1 к 4 или чуть лучше (за исключением тех случаев, когда контроллер держит данные в кэше до тех пор, пока не перезапишет весь блок данных). При последовательной записи картина меняется: RAID10 имеет всё те же расходы 1 к 2, а вот у RAID5 расходы падают вплоть до 1 к 1.125.
Еще один вариант - RAID6. Для такого типа массива формула расчёта меняется совсем чуть: вместо одной контрольной суммы контроллер читает и пишет 2 суммы. В итоге:
Т = ((D-C) + 2 чтения контрольных сумм) + (C+2 записи контрольных сумм))
Сразу рассчитаем накладные расходы при записи, чтобы мочь сравнить RAID6 с RAID5:
Для изменения 2 блоков: 7-2+2=7 IO чтения и 2+2=4 IO записи. В сумме 11 IO у RAID6 против 10 у RAID5.
Для изменения 6 блоков результаты будут следующие: 7-6+2=3 IO чтения и 6+2=8 IO записи. В сумме 11 IO против 9 IO у RAID5. То есть, у RAID6 расходы на 10-20% выше, чем у RAID5, в зависимости от ситуации. При этом RAID6 точно имеет наименьшие расходы, когда записывается блок целиком, а не какая-либо его часть.
Суммируя всё выше сказанное.
Пример #1: База данных
Представим, что у вас есть высоконагруженная БД для которой у вас выделен отдельный LUN на массиве. Допустим, что пишет она блоками по 8кБ, а шаблон доступа у неё случайный. В таком случае больше всего на задержки влияют время позиционирования головки и задержка из-за вращения диска. В итоге, лучше использовать как можно меньше дисков для записи, так как каждый диск, которому нужно будет записать данные, будет вынужден искать эти данные на диске. Поэтому использование 8кб размера блока данных на RAID массиве тоже будет оптимальным вариантом. Если смотреть на накладные расходы, то, за счёт случайного шаблона доступа, у RAID5 накладные расходы на запись буду 1 к 4, тогда как у RAID10 – 1 к 2. Это значит, что вам понадобится меньше дисков, чтобы добиться того же уровня производительности что и при использовании RAID5. И, наконец, размер диска: если БД относительно маленькая, то стоимость использования RAID10 может оказаться ниже, чем у RAID5. Почему так? Представим, что вы используете SAS диски со скоростью вращения шпинделя 15000rpm, каждый из которых выдаёт 200IOPS, тогда как размер вашей базы составляет 500МБ, и она требует 600 IOPS от СХД для чтения и столько же для записи.
Для RAID10 понадобится:
Чтение: 600/200=3 диска
Запись: 600/200*2= 6 дисков.
Поскольку в расчете участововал худший сценарий - 100% операций записи, то в итоге получается, что для создания RAID массива нужной производительности нужно 6 дисков.
Требования для RAID5:
Чтение: 600/200=3 диска
Запись: 600/200*4=12 дисков.
В итоге 12 дисков. Однако учитывая время пересборки такого массива, и её влияние на производительность, построение RAID5 такого размера нежелательно.
Пример #2: Приложение по работе с видео.
В данном случае у нас есть видео приложение, которое пишет много данных на массив. Допустим, поток составляет 100МБ/с при размере блока в 1МБ, доступ 100% последовательный, а диски SATA.
Как мы уже видели, RAID5 очень эффективен при записи всего блока данных сразу. Если мы сделаем RAID5 из 5 дисков (4+1), размер блока на массиве 256кб (1МБ/4), то каждая запись на массив будет чётко попадать в блок. При скорости потока в 100МБ/с каждый диск должен быть в состоянии записывать данные со скоростью в 25МБ/с и обработать 31.25 IOPS. Как были рассчитаны требования к IOPS? Накладные расходы на запись составят 1 к 1.125, что даёт 125 IOPS на запись, тогда как дисков с данными у нас 4 -> 125/4= 31.25. Вполне реальный вариант для SATA дисков.
Основные типы RAID массивов, их плюсы и минусы

RAID0 (чередование) - данные разбиваются на блоки, которые пишутся на все диски по очереди. Требует минимум 2 диска. Плюс - в скорости, так как он растёт линейно с ростом количества дисков. Объём равен сумме объёма дисков. Минус - отсутствие резервирования, и выход 1 диска из строя означает потерю данных. Вывод: не рекомендовано к использованию в чистом виде.

RAID1 (зеркалирование) - данные пишутся на все диски зеркально. Требует минимум 2 диска. Плюс - скорость чтения растёт с добавлением количества дисков. Работоспособен, пока есть хоть 1 диск в группе. Минусы: накладные расходы составляют 2 к 1 (вопрос накладных расходов я раскрою ниже). Итоговый объём равен объёму одного диска. Вывод: самый простой способ организации избыточности.
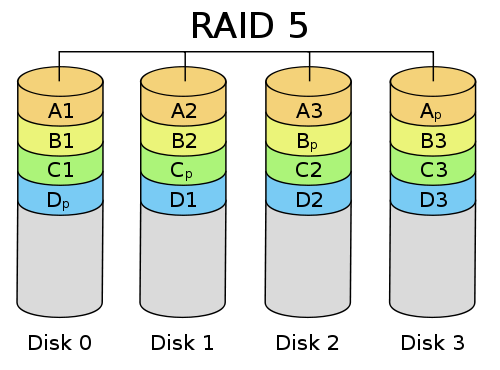
RAID5 (чередование данных с использованием контрольных сумм) - каждый следующий блок данных пишется на следующий диск, то есть по сути это RAID0, но для чётности данных используются контрольные суммы. Объём массива равен сумме объёма дисков минус объём самого маленького из них (используется для этих самых контрольных сумм). Требует минимум 3 диска. Плюсы: итоговый объём массива, распараллеливание чтения по всем дискам. Минусы: низкая скорость записи при случайно доступе, в случае выхода из строя одного из дисков массив переходит в режим деградации и начинает пересборку. Это приводит к падению производительности, а в случае выхода из строя еще одного диска - потерей данных. Время пересборки массива, учитывая объёмы современных дисков, может достигать нескольких дней. Надёжность дисков в массиве очень быстро и сильно снижается. Высокие накладные расходы

RAID6 (чередование данных с использованием двух контрольных сумм) - тоже самое, что и RAID5, только используются две разных контрольных суммы. Требует минимум 4 диска. Плюсы: способен выдержать выход из строя двух дисков. Минусы: еще медленнее, чем RAID5, а накладные расходы еще выше.
RAID10 (сочетание зеркалирования с чередованием) - Требует минимум 4 диска. Технически есть два типа RAID10 - RAID 0+1 (два RAID0 объединяют в зеркало) и RAID 1+0 (два зеркала объединяют в RAID0). Представим, что у нас есть 8 дисков и нам их нужно собрать в RAID. Если мы создадим RAID1+0, то получим 4 группы зеркальных дисков, на которые данные будут писаться как на RAID0. В случае с RAID0+1 мы получим 2 группы RAID0 по 4 дисков в каждой, данные на которые будут писаться зеркально.
Плюсы: чтение распараллеливается по всем дискам в массиве. Самый высокий уровень отказоустойчивости.
Минусы: у RAID0+1 низкая отказоустойчивость, так как у нас 2 RAID0 массива, который сам по себе не безопасен, и если из строя выйдет хотя бы 1 диск в массиве, то контроллер будет работать только со вторым RAID0 массивом. В случае же RAID1+0 если из строя выйдет 1 диск, то это повлияет только на его партнёра, но никак не весь массив в целом. В случае пересборки RAID10 общая производительность СХД не понизится. Итоговый объём данных равен половине объёма дисков.
В обзор не вошли RAID2 (побитовое чередование с контрольными суммами. Под суммы нужно n-1 дисков), RAID3 (побайтовое чередование с контрольными суммами. В отличие от RAID2 менее избыточен и не исправляет ошибки на лету), RAID4 (поблоковый RAID3). Основное отличие RAID3 и RAID4 от RAID5 в том, что для хранения контрольных сумм используется выделенный диск, в то время как RAID5 контрольные суммы размазывает по всем дискам в массиве.
И последнее: есть еще не очень широко применяющиеся уровни RAID - RAID50 и RAID60.Так же, как и в случае RAID10 это сочетание RAID5(6) с RAID0.
Накладные расходы у RAID5 и RAID10
То что скорость чтения отличается от скорости записи у RAID массивов отличается - это очевидный факт. С чтением всё просто - оно происходит со всех дисков сразу. С записью немного по другому: у RAID10 эффективная запись происходит только на половину дисков массива (вторая половина массива пишет то же самое, поэтому распараллелить запись можно на двое меньшее количество дисков), и в итоге накладные расходы составляют 2 к 1 (2 IO для 1 записи), и они не меняются ни в каком случае. У RAID5 же производительность меняется в зависимости от количества и последовательности данных. Допустим вам надо перезаписать один единственный блок. Для этого контроллеру надо прочитать блок данных и его контрольную сумму, потом рассчитать новую, и записать блок данных и его контрольную сумму. В итоге мы имеем пропорцию 4 к 1. То есть 4 IO для 1 записи.
Всё становится еще хуже, если необходимо перезаписать часть блока данных. В таком случае контроллеру нужно прочитать весь блок данных, за исключением перезаписываемых, посчитать контрольную сумму и записать, в итоге, данные и новую контрольную сумму. В итоге накладные расходы в этом случае посчитать немного сложнее: если считать D за общее количество дисков в массиве, C как количество изменяемых блоков, то Т – общее количество IOPS равно:
Т = ((D-C) + 1 чтение контрольной суммы) + (C+1 запись контрольной суммы))
Но соотношение про 4 к 1 у RAID5 чисто теоретическое. На практике всё выглядит немного иначе. Допустим, у вас есть RAID5 состоящий из 9 дисков (8 с данными и 1 один с контрольными суммами). Контроллеру необходимо перезаписать 2 два сегмента в блоках данных. В таком случае формула будет выглядеть следующим образом: 8-2+1 = 7 IO чтения, после чего 2+1 = 3 IO записи. В итоге, для изменения 2 блоков данных контроллеру необходимо обработать 10 IO, а накладные расходы составят уже не 1 к 4, а 1 к 5.
Но, представим себе второй вариант: всё тот же RAID5 из девяти дисков, но изменить нужно уже 6 сегментов в блоках данных. И тогда всё меняется: 8-6+1=3 IO чтения, и 6+1=7 IO записи. В итоге для обработки 6 блоков данных контроллеру нужно обработать 10 IO, а накладные расходы составят уже 1 к 1.66.
А для полной перезаписи 8 блоков данных в данном случае понадобилось бы всего 9 IO, а накладные расходы составят 1 к 1.125.
В итоге, максимум производительности от RAID5 вы получите только, когда контроллер будет перезаписывать весь блок данных, чтобы задействовать мощности всех дисков массива. Некоторые компании, например ЕМС, стараются держать записываемые блоки в кэше, и перезаписывать данные в массиве, только когда контроллер сможет перезаписать весь блок данных.
В итоге: при случайной записи у RAID10 накладные расходы статичны – 1 к 2, а у RAID5 - 1 к 4 или чуть лучше (за исключением тех случаев, когда контроллер держит данные в кэше до тех пор, пока не перезапишет весь блок данных). При последовательной записи картина меняется: RAID10 имеет всё те же расходы 1 к 2, а вот у RAID5 расходы падают вплоть до 1 к 1.125.
Еще один вариант - RAID6. Для такого типа массива формула расчёта меняется совсем чуть: вместо одной контрольной суммы контроллер читает и пишет 2 суммы. В итоге:
Т = ((D-C) + 2 чтения контрольных сумм) + (C+2 записи контрольных сумм))
Сразу рассчитаем накладные расходы при записи, чтобы мочь сравнить RAID6 с RAID5:
Для изменения 2 блоков: 7-2+2=7 IO чтения и 2+2=4 IO записи. В сумме 11 IO у RAID6 против 10 у RAID5.
Для изменения 6 блоков результаты будут следующие: 7-6+2=3 IO чтения и 6+2=8 IO записи. В сумме 11 IO против 9 IO у RAID5. То есть, у RAID6 расходы на 10-20% выше, чем у RAID5, в зависимости от ситуации. При этом RAID6 точно имеет наименьшие расходы, когда записывается блок целиком, а не какая-либо его часть.
Суммируя всё выше сказанное.
Пример #1: База данных
Представим, что у вас есть высоконагруженная БД для которой у вас выделен отдельный LUN на массиве. Допустим, что пишет она блоками по 8кБ, а шаблон доступа у неё случайный. В таком случае больше всего на задержки влияют время позиционирования головки и задержка из-за вращения диска. В итоге, лучше использовать как можно меньше дисков для записи, так как каждый диск, которому нужно будет записать данные, будет вынужден искать эти данные на диске. Поэтому использование 8кб размера блока данных на RAID массиве тоже будет оптимальным вариантом. Если смотреть на накладные расходы, то, за счёт случайного шаблона доступа, у RAID5 накладные расходы на запись буду 1 к 4, тогда как у RAID10 – 1 к 2. Это значит, что вам понадобится меньше дисков, чтобы добиться того же уровня производительности что и при использовании RAID5. И, наконец, размер диска: если БД относительно маленькая, то стоимость использования RAID10 может оказаться ниже, чем у RAID5. Почему так? Представим, что вы используете SAS диски со скоростью вращения шпинделя 15000rpm, каждый из которых выдаёт 200IOPS, тогда как размер вашей базы составляет 500МБ, и она требует 600 IOPS от СХД для чтения и столько же для записи.
Для RAID10 понадобится:
Чтение: 600/200=3 диска
Запись: 600/200*2= 6 дисков.
Поскольку в расчете участововал худший сценарий - 100% операций записи, то в итоге получается, что для создания RAID массива нужной производительности нужно 6 дисков.
Требования для RAID5:
Чтение: 600/200=3 диска
Запись: 600/200*4=12 дисков.
В итоге 12 дисков. Однако учитывая время пересборки такого массива, и её влияние на производительность, построение RAID5 такого размера нежелательно.
Пример #2: Приложение по работе с видео.
В данном случае у нас есть видео приложение, которое пишет много данных на массив. Допустим, поток составляет 100МБ/с при размере блока в 1МБ, доступ 100% последовательный, а диски SATA.
Как мы уже видели, RAID5 очень эффективен при записи всего блока данных сразу. Если мы сделаем RAID5 из 5 дисков (4+1), размер блока на массиве 256кб (1МБ/4), то каждая запись на массив будет чётко попадать в блок. При скорости потока в 100МБ/с каждый диск должен быть в состоянии записывать данные со скоростью в 25МБ/с и обработать 31.25 IOPS. Как были рассчитаны требования к IOPS? Накладные расходы на запись составят 1 к 1.125, что даёт 125 IOPS на запись, тогда как дисков с данными у нас 4 -> 125/4= 31.25. Вполне реальный вариант для SATA дисков.



Добавлю есть еще один тип рейда,
ОтветитьУдалитьRAID-DP в системе хранения NetApp.
RAID-DP(два выделенных диска с четностью) требует минимум трех дисков. Плюсы: способен выдержать отказ двух любых дисков. Не имеет накладных расходов. Минусы: существует только в СХД NetApp.
Для ваших примеров
#1 Для RAID-DP понадобится
Чтение: 600/200=3диска+2 диска четности
Запись: 600/200=3диска+2 диска четности
Итого: 5 дисков для любого сценария.
#2 Так как в RAID-DP запись всегда последовательна и производится полным страйпом сразу на всю группу дисков то возвращаемся к варианту 1.
Кстати, хоть и не для производительности, но накладные расходы это еще и используемая емкость RAID группы по сравнению с общей емкостью всех дисков ее составляющей. Для RAID 10 это 50% доступной емкости, для максимальной RAID 6 группы (16 дисков) это 87,5%, а для RAID-DP (28 дисков) 92,86%.
ОтветитьУдалитьОтличный пост. Спасибо!
ОтветитьУдалитьdve, про RAID-DP, который взял себе от RAID6 и RAID4, я не писал просто потому, что это проприетарные типы массивов. Точно так могу сказать, что у EMC Symmetrix раньше был RAID-S, который напоминал RAID5. А еще у IBM есть RAID1-E. Но всё это узкие и не широкодоступные решения, потому в обзор они не входят.
ОтветитьУдалитьDmitry, всегда пожалуйста. Дальше будет больше.
У IBM есть ещё RAID 5E и 5EE.
ОтветитьУдалитьОсновное отличен их от 5 -ки в том что:
В 5e зармазана по дискам контроль четности
В 5ee контроль четности размазаному еще на hotspare диск,
т.е. Если в карзине 6 диском можно сделать
raid 5 где в работе используется 5 дисков 1 из которых четность + 1 диск hotspare
В raid 5e четность размазана по 5 дискам +1диск hotspare
В raid 5ee четность размазана по 6дискам с двойным котролем четности. Отличен от рейд 6 что вый из стоя могут 2 диска, но последовательно.
С интересом прочитал, но определенную путаницу вносит используемая терминология: "блоки", "сегменты" и т.п. (особенно это утяжеляет восприятие блока про накладные расходу).
ОтветитьУдалитьЕсть стандартная терминология, принятая в SNIA. Последние лет 5 не устаю рекомендовать к прочтению DDF от SNIA: http://www.snia.org/tech_activities/standards/curr_standards/ddf
Кроме того, DDF содержит описание и таких "проприетарных" уровней как RAID1E и т.п. (они к IBM привязаны очень условно, если не сказать более категорично).
Использование стандартных терминов strip и stripe сильно упрощают понимание текста про RAID. Например, снижение накладных расходов на запись в RAID5/6 актуально только в том случае, когда записываемые данные попадают в разные strip одного stripe. Важно упомянуть, что контроллеры стараются максимально снизить расходы, собирая full stripe в тех случаях, когда такая возможность есть и линейная запись обычно весьма эффективна.
Выбор strip size (хотя большинство производителей используют "альтернативный" терминологии SNIA вариант - stripe size) вообще весьма нетривиален - далеко не всегда уменьшение приводит к росту производительности даже на операциях маленькими блоками. Я бы советовал максимально следовать "умолчанию" производителя для данного типа нагрузки - очень многое зависит от особенностей работы микрокода системы. Немаловажное значение для производительности имеет используемый контроллером размер блока памяти в кэше (и, разумеется, возможность его менять).
Встречаются в тексте и явные ошибки (вероятно описки), например "Объём массива равен сумме объёма дисков минус объём самого маленького из них" для RAID5. Из этого предложения следует, что если взять 4 диска по 200ГБ и 1 диск 100ГБ, то объем RAID5 из них будет 800ГБ, хотя на самом деле всего 400ГБ.
Андрей, я использовал слова "блоки" и "сегменты" так как именно чаще всего именно эти слова и используются в русском языке для обозначения этих понятий.
ОтветитьУдалитьКроме того, "взять 4 диска по 200ГБ и 1 диск 100ГБ" - крайняя форма идиотизма. Я не верю, что люди читающие этот блог могут такое выдать.
Данная фраза имеет в виду следующее: несмотря на то, что на шильдике размер у дисков в ГБ одинаковый, то в МБ - нет, и по размеру самого маленького в МБ дисках и будет создан массив, и его же объём будет вычтен из общего объёма для хранения контрольных сумм.
Константин, из интереса тщательно погуглил на предмет использования терминов "блок" и "сегмент" в применении к RAID. В редких случаях данное сочетание действительно встречается (даже в MSDN приметил), но во _всех_ найденных вариантах два термина используются исключительно в виде синонимов. Ну да ладно, может быть true storage geeks :) действительно так пользуются терминами. Оставим на их совести. Но на практике, один часто использует "размер блока" для обозначения strip size, второй - для блока файловой системы, третий - в лучшем случае для stripe size, а то и вообще для чего-то только ему понятного. Вот тут и начинается путаница и беседа сводится к пустому спору и непониманию друг друга.
ОтветитьУдалитьПонятно, что использовать диски разного размера в одной RAID-группе редко бывает оправданно, но я говорю вовсе не об этом. Лишь исключительно про точность формулировок. Я прекрасно понимаю что {скорее всего} имелось в виду, но формулировка говорит обратное. Ответьте на простой вопрос - для кого написан Ваш текст? Для тех, кто только пытается разобраться в азах, или для тех, кто прекрасно знает всю кухню изнутри? Если для последних, то они и так знают, как работает RAID0 (и не путают с RAID1), а если для первых, то вот они-то и запутаются сразу на вычислении объема RAID5 (если уж прорвались сквозь блоки и сегменты).
Кстати, "сегмент" в Вашей терминологии это сектор диска или размер ячейки в кэше, или несколько последовательных блоков, или что-то еще? Специально перечитал еще раз и окончательного мнения не сформировал. ;)
Андрей, я перед тем как публиковать текст здесь дал его почитать людям немного далёким от сайзинга СХД и выбора типа RAID массивов - по результатам были переписаны непонятные им места.
ОтветитьУдалитьТак что, я думаю, что человек который будет это читать или всё поймёт, или отпишет мне в комментарии или почту с вопросами, тех кто знает кухню изнутри - не так много, для многих raid10 это raid1+0, но не вариант 0+1.
Сегмент - это часть блока массива, который по SNIA strip, не обязательно последовательный. Касательно кэша на контроллерах я тут вообще этой темы не касался, но руки как-то дойдут поковырять работу таковых у Adaptec и LSI, тогда и о них напишу отдельно.
Коллеги, предлагаю в данном случае не углубляться в глубокие дискуссии по определениям блоков по SNIA и ище с ними. Смысл статьи - обзорный, дать понять *принцип* работы и расчета производительности людям, далеким от СХД.
ОтветитьУдалитьТочно так же предлагаю не обсуждать "гипотетических" читателей, которые запутаются. Если кто-то запутается, то существуют комментарии, в которых можно уточнить, либо можно задать вопрос лично, e-mail / skype. Мои контакты опубликованы, Константин своих тоже не скрывает.
Отличная статья, огромное спасибо Константину!
ОтветитьУдалитьВсегда пожалуйста. На очереди еще статьи.
ОтветитьУдалитьЗдесь было бы неплохо ещё добавить информацию о производительности каждого из рейдов в случае выхода из строя 1 для R5, 1 и 2 для R6 и половины для R10/R1.
ОтветитьУдалитьЭтот комментарий был удален автором.
ОтветитьУдалитьЭтот комментарий был удален автором.
ОтветитьУдалитьТак почему бы не назвать самым производительным RAID0, до определенного количества дисков в наборе и объявить победителем в отказоустойчивости RAID6 и оставить в покое RAID1+0 на его законном месте, ниже отказоустойчивости RIAD6?
ОтветитьУдалить