Мне довелось присутствовать на добром десятке презентаций по виртуализации бизнес приложений, и в большинстве случаев оставалось чувство недоговоренности. Словно я пропустил самую главную часть. Вендоры средств виртуализации утверждают, что business critical приложения в виртуальных машинах прекрасно работают. Вендоры железа презентуют свли линейки hi end оборудования для этих приложений.
Но что же такое на самом деле приложения класса "business critical" и чем они отличются от остальных? Поскольку обычно при разговоре мы многое подразумеваем само собой разумеющимся, а в итоге запутываемся, то давайте начнем с самого начала.
Так что же тогда бизнес-критичное приложение? Для этого надо разобраться с остальными словами.
Но здесь снова вопрос - почти любое приложение, кроме, разве что, пасьянса "Косынка", используется и может быть использовано для получения прибыли. Тот же Skype может использоваться для общения с поставщиками и клиентами.
В чем разница между просто бизнес-приложениями и бизнес-критичными приложениями?
Продолжим. Вообще получается, что есть некоторая шкала влияния приложений на бизнес предприятия, и она по сути непрерывна, так где же нужно провести черту и на основании чего? И как потом защищать эти приложения?
RPO - Recovery Point Objective, целевая точка восстановления. Т.е. грубо говоря, сколько данных допустимо потерять при аварии.
RTO - Recovery Time Objective, целевое время восстановления. Т.е. грубо говоря, сколько можно простоять при аварии.
 Представим это в виде графика, с нулем в точке аварии. По горизонтали шкала времени, по вертикали деньги. Соотв. точка восстаноления будет находиться в отрицательную сторону по времени и означать потерю данных за N часов. А время восстановления в положительную сторону и соотв. означать время простоя до возобновления работы приложения. Но к чему тут деньги?
Представим это в виде графика, с нулем в точке аварии. По горизонтали шкала времени, по вертикали деньги. Соотв. точка восстаноления будет находиться в отрицательную сторону по времени и означать потерю данных за N часов. А время восстановления в положительную сторону и соотв. означать время простоя до возобновления работы приложения. Но к чему тут деньги?
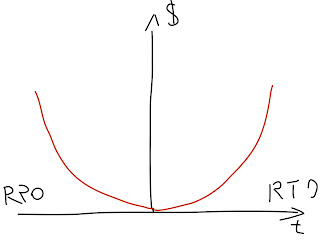 А вот к чему. Чем больше данных будет потеряно, и чем дольше простой - тем больше денег теряет предприятие. Но я хочу отдельно отметить - вот этот график зависимости делает не ИТ подразделение. Его делает бизнес-подразделение, а ИТ принимает на веру и в качестве руководства к действию.
А вот к чему. Чем больше данных будет потеряно, и чем дольше простой - тем больше денег теряет предприятие. Но я хочу отдельно отметить - вот этот график зависимости делает не ИТ подразделение. Его делает бизнес-подразделение, а ИТ принимает на веру и в качестве руководства к действию.
Т.е. по умному перед тем как говорить о бизнес-приложениях и их защите, нужно сначала произвести полную инвентаризацию приложений и данных, и сделать их классификацию. После чего построить зависимости приложений друг от друга и от данных. И прийти с получившимся счастьем к коммерческому, например, директору и получить от него стоимость часа потери данных и часа простоя для каждого приложения. Пока нет стоимости - все разговоры о бизнес-приложениях и их защите бессмысленны, и по сути являются методом научного тыка пальцем в небо.
Отдельно хочу отметить, что график может быть очень разным для каждого приложения, в зависимости от самого приложения и даже отрасли. И далеко не всегда он будет симметричным.
Ок, получили мы этот график, что дальше делать?
 А вот здесь на график накладывается кривая стоимости защиты от простоя и потери данных. Нетрудно заметить, что существуют точки пересечения этих кривых.
А вот здесь на график накладывается кривая стоимости защиты от простоя и потери данных. Нетрудно заметить, что существуют точки пересечения этих кривых.
 В этих точках стоимость защиты сравнивается с потерями, и именно эти две магические точки являются для нас руководством к действию. Все, что ближе к точке аварии, будет вести к малым потерям денег из-за простоя, но потери денег на защиту будут больше, чем стоимость простоя. Т.е. все, что между этими двумя точками, экономически невыгодно.
В этих точках стоимость защиты сравнивается с потерями, и именно эти две магические точки являются для нас руководством к действию. Все, что ближе к точке аварии, будет вести к малым потерям денег из-за простоя, но потери денег на защиту будут больше, чем стоимость простоя. Т.е. все, что между этими двумя точками, экономически невыгодно.
С другой же стороны, ИТ получает в свои руки экономическое обоснование для средств защиты - резервного копирования, кластеризации и т.д. прямо из рук бизнес-подразделения. "Потратив 10 руб на систему резервного копирования, мы ограничиваем риск потери данных 10-ю же рублями в стоимости данных".
И вот здесь появляются две новые аббревиатуры из трех букв.
SLO - Service Level Objective, целевой уровень сервиса. Т.е. на каждое приложение и класс данных ИТ вместе с бизнес-подразделением устанавливают эти две целевые точки RPO/RTO.
SLA - Service Level Agreement, соглашение об уровне сервиса. По сути это просто документ с описанным SLO и опционально штрафными санкциями за его нарушение. Разумеется, штраф опционален только для внутреннего документа, и совершенно необходим, если SLA заключается с внешним поставщиком услуг.
На этом на сегодня все, в дальнейшем мы поговорим о влиянии виртуализации на все эти аббревиатуры.
Но что же такое на самом деле приложения класса "business critical" и чем они отличются от остальных? Поскольку обычно при разговоре мы многое подразумеваем само собой разумеющимся, а в итоге запутываемся, то давайте начнем с самого начала.
Приложение
Приложение - это компьютерная программа, предназначенная для выполнения пользовательских задач. В этом его отличие от операционной системы, предназначенной для того, чтобы быть прослойкой между железом и приложениями. И системных программ, обслуживающих ту или иную задачу по обеспечению функционирования всего комплекса (например дефрагментатор).Так что же тогда бизнес-критичное приложение? Для этого надо разобраться с остальными словами.
Бизнес
Бизнес - деятельность, направленная на извлечение прибыли, если говорить упрощенно. Т.е. бизнес-приложения - это приложения, используемые в основной деятельности предприятия, и от функционирования которых зависит получение прибыли.Но здесь снова вопрос - почти любое приложение, кроме, разве что, пасьянса "Косынка", используется и может быть использовано для получения прибыли. Тот же Skype может использоваться для общения с поставщиками и клиентами.
В чем разница между просто бизнес-приложениями и бизнес-критичными приложениями?
Business critical
Бизнес-критичным считается приложение, недоступность которого влечет за собой ощутимые последствия для бизнеса, т.е. прибыли предприятия. Вплоть до полной остановки деятельности. Да, я понимаю, что есть теории значительно более продвинутые и с отличной терминологией, но в данном случае я не ставлю перед собой целей заменить их. Это пояснение для технических специалистов, вообще не сталкивавшихся с ITIL и Business Continuity.Продолжим. Вообще получается, что есть некоторая шкала влияния приложений на бизнес предприятия, и она по сути непрерывна, так где же нужно провести черту и на основании чего? И как потом защищать эти приложения?
RPO, RTO, SLO, SLA
Для начала для приложения (и/или данных) нужно определить такие два показателя как RPO и RTO.RPO - Recovery Point Objective, целевая точка восстановления. Т.е. грубо говоря, сколько данных допустимо потерять при аварии.
RTO - Recovery Time Objective, целевое время восстановления. Т.е. грубо говоря, сколько можно простоять при аварии.


Т.е. по умному перед тем как говорить о бизнес-приложениях и их защите, нужно сначала произвести полную инвентаризацию приложений и данных, и сделать их классификацию. После чего построить зависимости приложений друг от друга и от данных. И прийти с получившимся счастьем к коммерческому, например, директору и получить от него стоимость часа потери данных и часа простоя для каждого приложения. Пока нет стоимости - все разговоры о бизнес-приложениях и их защите бессмысленны, и по сути являются методом научного тыка пальцем в небо.
Отдельно хочу отметить, что график может быть очень разным для каждого приложения, в зависимости от самого приложения и даже отрасли. И далеко не всегда он будет симметричным.
Ок, получили мы этот график, что дальше делать?


С другой же стороны, ИТ получает в свои руки экономическое обоснование для средств защиты - резервного копирования, кластеризации и т.д. прямо из рук бизнес-подразделения. "Потратив 10 руб на систему резервного копирования, мы ограничиваем риск потери данных 10-ю же рублями в стоимости данных".
И вот здесь появляются две новые аббревиатуры из трех букв.
SLO - Service Level Objective, целевой уровень сервиса. Т.е. на каждое приложение и класс данных ИТ вместе с бизнес-подразделением устанавливают эти две целевые точки RPO/RTO.
SLA - Service Level Agreement, соглашение об уровне сервиса. По сути это просто документ с описанным SLO и опционально штрафными санкциями за его нарушение. Разумеется, штраф опционален только для внутреннего документа, и совершенно необходим, если SLA заключается с внешним поставщиком услуг.
На этом на сегодня все, в дальнейшем мы поговорим о влиянии виртуализации на все эти аббревиатуры.



А можно ли по-подробнее про механизмы, как именно "перед тем как говорить о бизнес-приложениях и их защите, нужно сначала произвести полную инвентаризацию приложений и данных, и сделать их классификацию. После чего построить зависимости приложений друг от друга и от данных."? Какие существуют средства автоматизации построения классификаций и зависимостей?
ОтветитьУдалитьЕсть множество средств от самых разных вендоров.
УдалитьVMware предлагает vCenter Application Discovery Manager и vCenter Infrastructure Navigator
Ну ты уж настолько то не упрощай, а то потом "технические специалисты" столкнутся с Business Continuity и придут ругаться ;)
ОтветитьУдалитьПересечение этих кривых - это некоторое лукавство, хотя и распространенное. Почему надо потратить X денег, чтобы не потерять еще X? А может быть, лучше потратить X/2, и принять риск потери 3X? На практике - бизнес определяет целевые показатели, исходя из различных критериев (кроме денег, тут может быть, например, репутационный риск, или compliance), а в ответ IT говорит, за сколько денег оно может их достичь. И если соотношение cost/benefit адекватное - тогда уже денег на проект дают.
Леш, ну ты знаешь, сегодняшнее состояние ИТ специалистов в плане понимания даже RPO / RTO ни разу не радует. Вот зачем нужна репликация и почему нельзя обойтись просто бэкапом.
УдалитьПонимаешь, я ведь по сути не написал ничего, что не рассказываю на каждой второй встрече. Это новый неведомый мир для технарей, и может быть он выглядит несколько упрощенно, почти на уровне детских сказок для тебя. Но у нас с тобой разные целевые аудитории и разные цели. Моя цель - объяснить почему мы говорим именно об этом, почему для задачи выбирается 8-контроллерная СХД класса Hi-End, а не 2-контроллерная класса Mid-Range. Или наоборот. Цель - показать на пальцах, откуда ноги растут.
Правильно-правильно! Сколько занимался выбором железа/софта, не было ни единой другой причины, кроме как "а, давайте, чтобы побольше ядер, гигабайтов, и pro/enterprise версий"!
УдалитьАнтон, привет.
ОтветитьУдалитьА вот на тему СХД давай поподробнее :)
Почему для задачи выбирается 8-контроллерная СХД (ну и там далее по тексту), а не более дешевая mid-range. Желательно с примерами из практики ;)
http://www.sysadministrator.ru/www
ОтветитьУдалить