Проблема:
1. "Правый клик / Guest / Install/Upgrade VMware Tools / Automated" практически сразу выдает ошибку "Error upgrading VMware Tools"
2. При апгрейде через интерфейс VMware Tools в гостевой Windows (кнопка "Upgrade") ничего не происходит.
3. Апгрейд в интерактивном режиме проходит нормально.
Существует статья в KB: Upgrading VMware Tools may fail when using Automatic Tools Upgrade in the vSphere Client
Решение: удалить VMwareToolsUpgrader.exe из %Temp% (обычно C:\Windows\Temp) и перезапустить апгрейд.
Алексей Тараненко любезно помог с PowerShell скриптом для автоматизации процесса.
четверг, 29 июля 2010 г.
понедельник, 26 июля 2010 г.
HA/DRS и нормализованные Shares
Неделю назад я уже упомянул о важном нововведении в vSphere 4.1, нормализованных shares.
Что же это такое?
При failover'е HA помещает ВМ в корневой ресурс-пул, и если при этом ВМ сама находилась в ресурс-пуле и имела высокое значение shares, то она будет иметь то же самое значение shares и после failover'а.
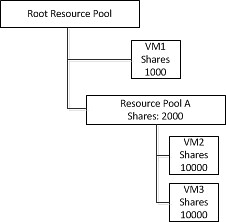
Предположим, что у нас есть 3 ВМ, 2 из которых находятся в специальном ресурс-пуле Resource Pool A. У VM1 1000 shares, у Resource Pool A - 2000. При этом в ресурс пуле находятся еще 2 ВМ, каждая из которых имеет по 10000 shares. Напомню, что shares в данном случае действуют только в пределах ресурс-пула, и обе ВМ имеют соотв. по 50%. Т.е. VM1 имеет 33% ресурсов, VM2 и VM3 по 50% от 66% ресурс-пула -> все три ВМ имеют по 33% ресурсов.
Что же это такое?
При failover'е HA помещает ВМ в корневой ресурс-пул, и если при этом ВМ сама находилась в ресурс-пуле и имела высокое значение shares, то она будет иметь то же самое значение shares и после failover'а.
Предположим, что у нас есть 3 ВМ, 2 из которых находятся в специальном ресурс-пуле Resource Pool A. У VM1 1000 shares, у Resource Pool A - 2000. При этом в ресурс пуле находятся еще 2 ВМ, каждая из которых имеет по 10000 shares. Напомню, что shares в данном случае действуют только в пределах ресурс-пула, и обе ВМ имеют соотв. по 50%. Т.е. VM1 имеет 33% ресурсов, VM2 и VM3 по 50% от 66% ресурс-пула -> все три ВМ имеют по 33% ресурсов.
пятница, 23 июля 2010 г.
2 года в эфире
Вот так в летнем угаре 2010 года, в 36 градусов жары и не заметил, что блогу 9го июля исполнилось два года.
 Хочется подвести итоги 2х лет активного участия в сообществе.
Хочется подвести итоги 2х лет активного участия в сообществе.
- Написано 260 постов в блоге
- 4500 комментариев на форуме VMware - общее 19е место и 1е в русскоязычном разделе
- Global User Moderator форума VMware
- дважды VMware vExpert
- VMware User Group Russia Leader (вместе с Михаилом Михеевым)
- Организовано 2 крупнейших встречи VMUG Russia, собравших в Москве почти по 100 человек
- Открыта первая региональная VMUG в Нижнем Новгороде
среда, 21 июля 2010 г.
HA: если не хватает ресурсов
Как вы, наверное, уже помните, при наступлении HA события агенты сначала проверяют наличие свободных ресурсов. Но что, если ресурсов недостаточно? Как все это работает?
А вот как:
Вопрос: а сколько ВМ будет ждать в очереди?
Ответ: пока не появятся свободные ресурсы.
Вопрос: как это сочетается с das.vmrestartcount?
Ответ: никак не сочетается, das.vmrestartcount отвечает за количество попыток перезапуска ВМ при достаточных ресурсах. В данном случае рассматривается ситуация с недостаточными ресурсами и перезапуска не происходит. Как только ресурсов станет достаточно - вступит в действие das.vmrestartcount.
А вот как:
Процесс vpxa слушает сообщения hostd об изменениях уровня доступности ресурсов (а именно изменениях незарезервированных ресурсов) и пересылает информацию процессу aam, принимающему решения о failover'е. Но чтобы не спамить aam, vpxa ждет пока изменение составит как минимум 5%. Получив сообщение об изменении доступности ресурсов aam проверяет, нет ли в очереди на failover виртуальных машин, ожидающих ресурсов, и если доступных ресурсов становится достаточно, то failover происходит - машина перезапускается.
Вопрос: а сколько ВМ будет ждать в очереди?
Ответ: пока не появятся свободные ресурсы.
Вопрос: как это сочетается с das.vmrestartcount?
Ответ: никак не сочетается, das.vmrestartcount отвечает за количество попыток перезапуска ВМ при достаточных ресурсах. В данном случае рассматривается ситуация с недостаточными ресурсами и перезапуска не происходит. Как только ресурсов станет достаточно - вступит в действие das.vmrestartcount.
понедельник, 19 июля 2010 г.
vNetwork: Массовое переключение ВМ в другую портгруппу
Предположим, у вас меняется сетевая политика для виртуальных машин и вы создаете новые портгруппы. Или вы решили мигрировать на Distributed vSwitch. Соотв. есть много (поэтому вручную не вариант, или просто лень) ВМ, подключенных в одну портгруппу, и их надо переключить в другую.
Решение - PowerShell! :)
Как это сделал я для своего тестового кластера. Сначала создал Distributed vSwitch с одним аплинком (с каждого хоста) и на нем новую портгруппу для ВМ. Затем переключил пару включенных машин вручную, проверив, что они остались доступны. И оставшиеся N-цать выключенных переключил уже скриптом:
Строго говоря, можно переключать и включенные машины, проблем с ними не возникает.
Решение - PowerShell! :)
Как это сделал я для своего тестового кластера. Сначала создал Distributed vSwitch с одним аплинком (с каждого хоста) и на нем новую портгруппу для ВМ. Затем переключил пару включенных машин вручную, проверив, что они остались доступны. И оставшиеся N-цать выключенных переключил уже скриптом:
Get-Cluster "Cluster" | Get-VM | Where-Object {$_.PowerState -eq "PoweredOff"} | Get-NetworkAdapter | where { $_.Name -eq "Network Adapter 1" } | Set-NetworkAdapter -NetworkName "dv VM Network" -Confirm:$false
Строго говоря, можно переключать и включенные машины, проблем с ними не возникает.
Новые HA Maximums в vSphere 4.1 и интеграция с DRS
Есть несколько изменений в vSphere 4.1, на которые стоит обратить внимание. Одно из очень приятных изменений в Configuration Maximums.
Новые максимумы HA
Новые максимумы HA
- 32 хоста в кластере
- 320 ВМ на хост
- 3,000 ВМ на кластер
- у вас может быть 10 хостов с 300 ВМ на каждом
- или 20 хостов со 150 ВМ
- или 32 с 93 ВМ
Выбор HA Primary Nodes в vSphere 4.1
В VMware HA есть очень важная вещь, называемая Primary Nodes. Проблема с Primary Nodes заключается в том, что нельзя контролировать какие именно хосты станут Primary, что соотв. негативным образом отражается на отказоустойчивости инфраструктуры, построенной на блейд серверах. Если все Primary хосты окажутся в одной блейд-корзине, то при падении этой корзины полностью ложится HA.
В vSphere 4.1 появилась новая тонкая настройка HA - предпочитаемые Primary Nodes.
Внимание! Эта функциональность не является даже экспериментальной, она просто не поддерживается, и категорически не рекомендуется к использованию в продуктивной среде.
Источник: Duncan Epping (yellow-bricks.com)
В vSphere 4.1 появилась новая тонкая настройка HA - предпочитаемые Primary Nodes.
das.preferredPrimaries = hostname1 hostname2 hostname3Разделять список хостов можно пробелом или запятой. Также необязательно указывать обязательно пять хостов, можно меньше (тогда оставшиеся будут выбраны традиционным способом) или больше (тогда Primary станут первые 5 из них).
или
das.preferredPrimaries = 192.168.1.1,192.168.1.2,192.168.1.3
Внимание! Эта функциональность не является даже экспериментальной, она просто не поддерживается, и категорически не рекомендуется к использованию в продуктивной среде.
Источник: Duncan Epping (yellow-bricks.com)
среда, 14 июля 2010 г.
Upgrade to vSphere 4.1 - первые грабли с vCenter
Продолжаем увлекательный академический бег по граблям.
Итак, как известно, VMware отказывается от 32битных систем. Поэтому те, кто собрался апгрейдиться до 4.1, наверняка подумали о том, чтобы заодно поменять и ОС на машине с vCenter до, скажем, 2008 R2.
Здесь закопана одна собака. Если снести полностью все, что было (считаем, что БД удаленная), и попытаться поставить еще пахнущий краской vCenter 4.1 на такую же свежую Windows и при этом подключиться к старой базе (мы ведь не хотим терять конфигурации), то можно получить следующее сообщение: "Setup located a vCenter Server database but not the companion SSL certificates."
И vCenter отказывается ставиться дальше.
Лечение: ДО выноса старой системы необходимо сделать резервную копию SSL сертификатов.
Но что же делать, если вы сейчас читаете это уже постфактум, и сертификаты соотв. пропали бесследно? Ничего страшного, можно поставить свежий чистый vCenter на другую БД, и скопировать сертификаты у него. Или взять их от тестового vCenter, если он у вас есть. Правда в этом случае все хосты будут в состоянии "Disconnected", но подключить их назад дело нескольких минут.
По материалам KB Article: 1014314.
Итак, как известно, VMware отказывается от 32битных систем. Поэтому те, кто собрался апгрейдиться до 4.1, наверняка подумали о том, чтобы заодно поменять и ОС на машине с vCenter до, скажем, 2008 R2.
Здесь закопана одна собака. Если снести полностью все, что было (считаем, что БД удаленная), и попытаться поставить еще пахнущий краской vCenter 4.1 на такую же свежую Windows и при этом подключиться к старой базе (мы ведь не хотим терять конфигурации), то можно получить следующее сообщение: "Setup located a vCenter Server database but not the companion SSL certificates."
И vCenter отказывается ставиться дальше.
Лечение: ДО выноса старой системы необходимо сделать резервную копию SSL сертификатов.
- Для Windows 2003 "C:\Documents and Settings\All Users\Application Data\VMware\VMware Virtual Center\SSL\"
- Windows 2008 "C:\ProgramData\VMware\VMware VirtualCenter\SSL\"
Но что же делать, если вы сейчас читаете это уже постфактум, и сертификаты соотв. пропали бесследно? Ничего страшного, можно поставить свежий чистый vCenter на другую БД, и скопировать сертификаты у него. Или взять их от тестового vCenter, если он у вас есть. Правда в этом случае все хосты будут в состоянии "Disconnected", но подключить их назад дело нескольких минут.
По материалам KB Article: 1014314.
пятница, 9 июля 2010 г.
Анонс VMware vSphere 4.1
Как сообщает virtualization.info, анонс vSphere 4.1 запланирован на 13 июля. Пока неясно, будет ли это только официальное объявление или 13 июля vSphere 4.1 будет доступна для загрузки.
И немного хороших новостей для SMB: vSphere Essentials Plus теперь будет включать и VMotion!
И немного хороших новостей для SMB: vSphere Essentials Plus теперь будет включать и VMotion!
четверг, 8 июля 2010 г.
Особенности лицензирования новых многоядерных процессоров
Как известно, различные редакции vSphere позволяют использовать процессоры лишь с ограниченным количеством ядер.
vSphere Essentials, vSphere Essentials Plus, vSphere Standard и vSphere Enterprise - 6 ядерные.
vSphere Advanced и vSphere Enterprise Plus - 12 ядер.
VMware выпустила документ, разъясняющий особенности лицензирования vSphere.
Итак, если у вас есть лицензия с ограничением 6 ядер на процессор, и вы хотите использовать процессоры с большим количеством ядер, то придется:
1) купить апгрейд до лицензии с большим количеством ядер
ИЛИ
2) Комбинировать несколько лицензий на одном хосте. Т.е. например можно объединить 2 лицензии vSphere Enterprise для запуска на одном двенадцатиядерном процессоре.
Обращаю ваше внимание, что при этом нельзя поделить одну 12-ядерную лицензию на две 6-ядерных.
vSphere Essentials, vSphere Essentials Plus, vSphere Standard и vSphere Enterprise - 6 ядерные.
vSphere Advanced и vSphere Enterprise Plus - 12 ядер.
VMware выпустила документ, разъясняющий особенности лицензирования vSphere.
Итак, если у вас есть лицензия с ограничением 6 ядер на процессор, и вы хотите использовать процессоры с большим количеством ядер, то придется:
1) купить апгрейд до лицензии с большим количеством ядер
ИЛИ
2) Комбинировать несколько лицензий на одном хосте. Т.е. например можно объединить 2 лицензии vSphere Enterprise для запуска на одном двенадцатиядерном процессоре.
Обращаю ваше внимание, что при этом нельзя поделить одну 12-ядерную лицензию на две 6-ядерных.
среда, 7 июля 2010 г.
Миграция инфраструктуры на новый vCenter Server
Maish Saidel-Keesing поделился PowerShell скриптом для миграции всей виртуальной инфраструктуры на новый vCenter.
Что делает этот скрипт:
Что делает этот скрипт:
- Экспорт структуры папок с ВМ
- Экспорт местоположения ВМ в папках
- Экспорт разрешений (permissions)
- Экспорт дополнительных атрибутов (custom attributes) и комментариев (notes)
- Создание папок на новом vCenter
- Выключение DRS/HA
- Отключение ESX хостов от старого vCenter и подключение их к новому vCenter
- Включение DRS/HA
- Перемещение ВМ в соответствующие папки
- Применение разрешений
- Восстановление дополнительных атрибутов и комментариев
StarWind 5.4 вышел в public release
Хорошая новость от компании StarWind - iSCSI SAN версии 5.4 теперь доступен широкой публике.
О производительности этого решения я писал буквально вчера. А также хочу напомнить, что если у вас есть звание vExpert, VCP или MCP - вам полагается бесплатная лицензия :)
О производительности этого решения я писал буквально вчера. А также хочу напомнить, что если у вас есть звание vExpert, VCP или MCP - вам полагается бесплатная лицензия :)
Улучшения работы HA в vSphere 4.0 update 2
Одна из часто встречающихся проблем в среде с iSCSI/NFS и VMware HA до vSphere 4.0u2 - split brain.
Для начала попробую объяснить, что такое split brain. Предположим, что у нас такая инфраструктура:
В случае полной изоляции одного из хостов, включая сеть хранения данных, происходит следующее:
Оригинал: Duncan Epping
Для начала попробую объяснить, что такое split brain. Предположим, что у нас такая инфраструктура:
- 4 хоста
- iSCSI / NFS хранилище
- Isolation response: leave powered on
В случае полной изоляции одного из хостов, включая сеть хранения данных, происходит следующее:
- Хост ESX001 полностью изолирован, включая сеть хранения данных (у нас ведь iSCSI/NFS), но виртуальные машины не выключаются, поскольку ответ на изоляцию "leave powered on".
- Через 15 секунд оставшиеся неизолированными хосты начнут перезапускать виртуальные машины.
- Поскольку iSCSI/NFS сеть также изолирована от ESX001, блокировки на VMDK файлах истекут по таймауту, и оставшиеся хосты смогут загрузить ВМ.
- Когда ESX001 вернется из изоляции, у него все еще останутся в памяти запущенные VMX процессы. И теперь начнется "пинг-понг" с vCenter - ВМ начнут переключаться то на ESX001, то на другие хосты.
Оригинал: Duncan Epping
вторник, 6 июля 2010 г.
Производительность StarWind iSCSI 5.4 beta
В связи с открытием бета-тестирования новой версии StarWind iSCSI захотелось протестировать производительность в режиме HA с разными настройками кэша.
В качестве тестового стенда использовались блейды BL460c G6 (2 * Xeon 5550, 10 GB RAM. 2 * 300 GB SAS 10k) с Windows 2003 R2 32 bit, подключенные к коммутаторам Cisco 3020. По одному интерфейсу трафик отдавался наружу, второй служил для синхронизации, по гигабитному линку. Нагрузку генерировали виртуальные машины, расположенные в соседней блейд-корзине, при помощи IOMeter.
Все настройки по умолчанию, тонкая сетевая настройка машин с StarWind iSCSI не проводилась. Был создан HA диск размером 20 GB. Итак, результаты:
В качестве тестового стенда использовались блейды BL460c G6 (2 * Xeon 5550, 10 GB RAM. 2 * 300 GB SAS 10k) с Windows 2003 R2 32 bit, подключенные к коммутаторам Cisco 3020. По одному интерфейсу трафик отдавался наружу, второй служил для синхронизации, по гигабитному линку. Нагрузку генерировали виртуальные машины, расположенные в соседней блейд-корзине, при помощи IOMeter.
Все настройки по умолчанию, тонкая сетевая настройка машин с StarWind iSCSI не проводилась. Был создан HA диск размером 20 GB. Итак, результаты:
понедельник, 5 июля 2010 г.
HA: Как работает “das.maxvmrestartcount”?
В статье "HA Deepdive: Isolation" было написано о появившемся в vSphere 4.0 параметре das.maxvmrestartcount.
Так как же конкретно происходит перезапуск ВМ и какое влияение имеет этот параметр?
При наступлении HA события, т.е. падении хоста с запущенной виртуальной машиной, HA будет пытаться перезапустить машину на одном из хостов в кластере. Если попытка не удалась, то HA увеличивает на единицу счетчик попыток перезапуска. Первая повторная попытка будет произведена через две минуты, вторая - через 4, каждая последующая через 8 минут. И так до тех пор, пока ВМ не включится либо счетчик не превысит значение das.maxvmrestartcount.
Чуть более наглядно. Предположим, что хост рухнул в 11:59:45, тогда попытки перезапуска ВМ состоятся в:
За информацию благодарность Duncan Epping.
Так как же конкретно происходит перезапуск ВМ и какое влияение имеет этот параметр?
При наступлении HA события, т.е. падении хоста с запущенной виртуальной машиной, HA будет пытаться перезапустить машину на одном из хостов в кластере. Если попытка не удалась, то HA увеличивает на единицу счетчик попыток перезапуска. Первая повторная попытка будет произведена через две минуты, вторая - через 4, каждая последующая через 8 минут. И так до тех пор, пока ВМ не включится либо счетчик не превысит значение das.maxvmrestartcount.
Чуть более наглядно. Предположим, что хост рухнул в 11:59:45, тогда попытки перезапуска ВМ состоятся в:
- 12:00 (после 15 секундного таймаута)
- 12:02 (+2 минуты)
- 12:04 (+4 минуты)
- 12:12 (+8 минут)
- 12:20 (+8 минут)
- 12:28 (+8 минут)
За информацию благодарность Duncan Epping.
Обратная сторона "облака" - презентация
По просьбам читателей выкладываю презентацию от доклада, с которым я выступал на круглом столе CNews.
Подписаться на:
Комментарии (Atom)


