- 36!
- Что 36?
- А что приборы?
Примерно так на сегодня выглядит большинство синтетических тестов систем хранения данных. Почему так?
До относительно недавнего времени большинство СХД были плоскими с равномерным доступом. Что это означает?
Общее доступное дисковое пространство было собрано из дисков с одинаковыми характеристиками. Например 300 дисков 15k. И производительность была одинаковой по всему пространству. С появлением технологии многоуровневого хранения, СХД стали неплоскими - производительность различается внутри одного дискового пространства. Причем не просто различается, а еще и непредсказуемо, в зависимости от алгоритмов и возможностей конкретной модели СХД.
И все было бы не так интересно, не появись гиперконвергентные системы с локализацией данных. Помимо неравномерности самого дискового пространства появляется еще и неравномерность доступа к нему - в зависимости от того, на локальных дисках узла лежит одна из копий данных или за ней необходимо обращаться по сети.
Привычные синтетические тесты резко дают маху, цифры от этих нагрузок потеряли практический смысл. Единственный способ всерьез оценить подходит ли система - это пилотная инсталляция с перенесением продуктива. Но что делать, если на перенос продуктива не дает добро безопасность или это просто слишком долго / трудоемко. Есть ли способ оценки?
Сделаем вид, что мы продуктивная нагрузка, и нагрузим весь гиперконвергентный кластер. Смело вычеркиваем "100% random по всему объему" - этот тест не покажет ровным счетом ничего, кроме производительности самых нижних дисков. Т.е. 150-300 IOPS на узел (2-4 SATA).
Что для этого требуется?
1. Минимум по 1 машине с генератором нагрузки на узел.
2. Профили нагрузки, приближенные к продуктиву.
Для массовых нагрузок типа VDI необходимо создание репрезентативного количества машин. В идеале конечно полного, но поскольку большинство демо-систем - это 3-4 узла, то 3000-4000 ВМ на них конечно никак не запустить.
В моих цепких лапах оказался кластер Nutanix NX-3460G4, но тест применим к любой платформе, доступной на рынке. Более того, те же самые тесты можно проводить и для классических СХД, технология никак не меняется.
В качестве генератора нагрузки я взял FIO под управлением CentOS 7. Профили нагрузок от Nutanix XRay 2.2. Почему CentOS? Был дистрибутив под рукой, можно использовать любой другой Linux по вкусу.
Делаем несколько шаблонов ВМ под разный тип нагрузки.
1. Управляющая FIO - 1 vCPU, 2GB RAM, 20GB OS
2. DB - 1 vCPU, 2GB RAM, 20GB OS, 2*2 GB Log, 4*28 GB Data
3. VDI - 1 vCPU, 2GB RAM, 20GB OS, 10 GB Data
Создаем управляющую FIO. Ставим CentOS в минимальной установке на 20GB диск, остальные не трогаем.
После минимальной установки CentOS ставим FIO
# yum install wget
# wget http://dl.fedoraproject.org/pub/epel/testing/7/x86_64/Packages/f/fio-3.1-1.el7.x86_64.rpm
# yum install fio-3.1-1.el7.x86_64.rpm
Повторяем то же самое для машин шаблонов нагрузки. И прописываем FIO в автозагрузку на них.
Создаем файл /etc/systemd/system/fio.service
[Unit]
Description=FIO server
After=network.target
[Service]
Type=simple
ExecStart=/usr/bin/fio --server
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target# systemctl daemon-reload
# systemctl enable fio.service
# systemctl start fio.service
# firewall-cmd --zone=public --permanent --add-port=8765/tcp
Инфраструктура готова. Теперь нужна нагрузка.
Создадим список серверов FIO.
10.52.8.2 - 10.52.9.146
Удобно использовать для этого Excel.
Загружаем этот список на управляющую машину. На нее же загружаем конфиг-файлы FIO c нагрузкой.
fio-vdi.cfg
[global]
ioengine=libaio
direct=1
norandommap
time_based
group_reporting
disk_util=0
continue_on_error=all
rate_process=poisson
runtime=3600
[vdi-read]
filename=/dev/sdb
bssplit=8k/90:32k/10,8k/90:32k/10
size=8G
rw=randread
rate_iops=13
iodepth=8
percentage_random=80
[vdi-write]
filename=/dev/sdb
bs=32k
size=2G
offset=8G
rw=randwrite
rate_iops=10
percentage_random=20fio-oltp.cfg
[global]
ioengine=libaio
direct=1
time_based
norandommap
group_reporting
disk_util=0
continue_on_error=all
rate_process=poisson
runtime=10000
[db-oltp1]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdd
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp2]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sde
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp3]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdf
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp4]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdg
rw=randrw
iodepth=8
rate_iops=500,500
[db-log1]
bs=32k
size=2G
filename=/dev/sdb
rw=randwrite
percentage_random=10
iodepth=1
iodepth_batch=1
rate_iops=100
[db-log2]
bs=32k
size=2G
filename=/dev/sdc
rw=randwrite
percentage_random=10
iodepth=1
iodepth_batch=1
rate_iops=100Запустим FIO в для проверки правильности настроек и первичного прогрева дисков.
На управляющей ВМ
# fio --client
Минуты через 2-3 можно нажать Ctrl-C, иначе FIO отработает полный цикл из конфига - 2 часа.
Теперь подготовим площадку под массовое развертывание VDI нагрузки. Я создал совершенно непересекающуюся сеть с IPAM - гипервизор AHV перехватывает DHCP и выдает адреса сам.
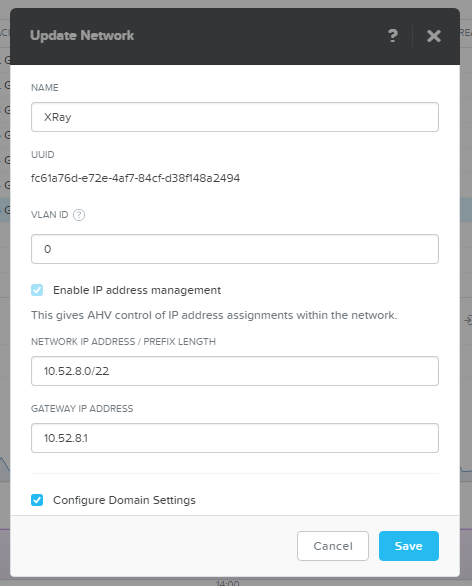
Поскольку AHV выдает адреса не по порядку, сделаем пул размером ровно под планируемую нагрузку - 400 ВМ (по 100 на хост).
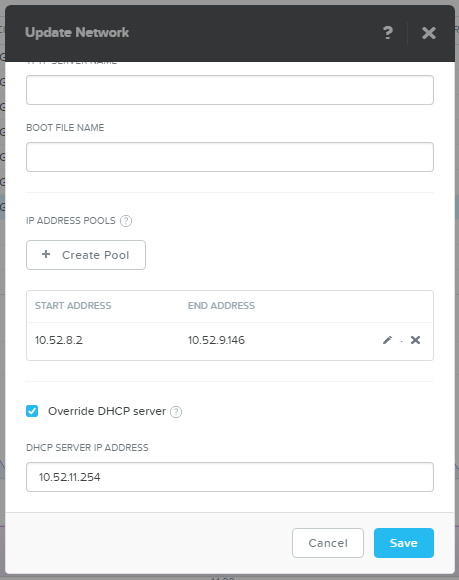
Создаем нагрузочные 400 машин VDI.
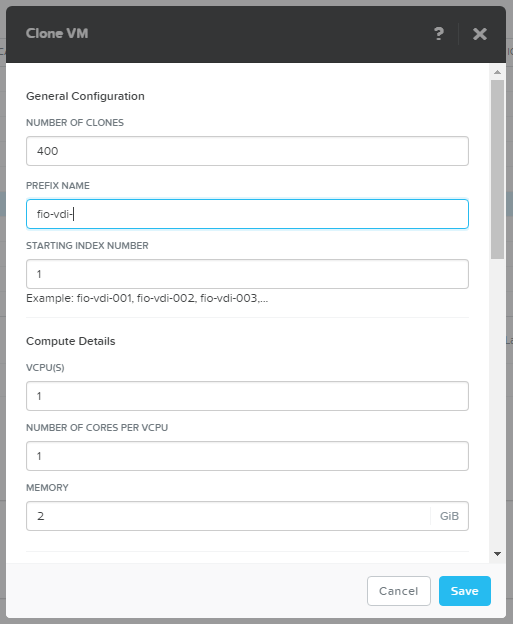
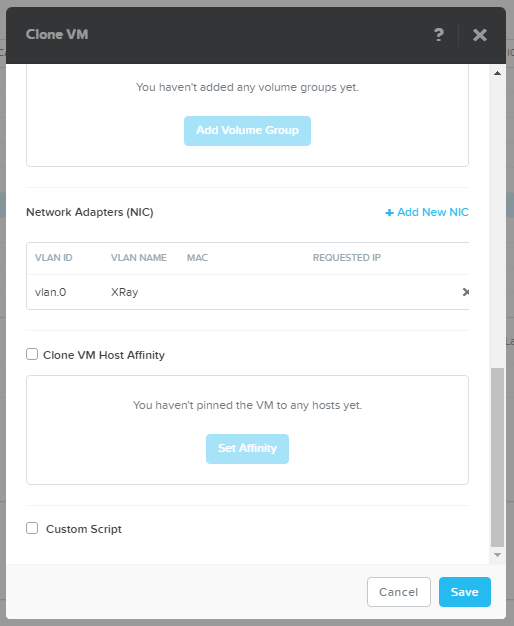
В принципе только создание сразу 400 машин уже интересный тест любой системы.
Как у нас справился немолодой уже кластер Nutanix?

2 минуты. Мне кажется, отличный результат.
Теперь включаем машины.
На Nutanix CVM
# acli vm.on fio-vdi-*
Ну и теперь самое время врубить полный газ!
С управляющей FIO
# fio --client vdi.list vdi.cfg
Примерно так ваша СХД будет себя чувствовать под 400 ВМ со средней офисной VDI нагрузкой.
Так же в статье указаны профили для средней OLTP и DSS БД. Их, конечно не по 400, но штук 6-8 можно запустить и попробовать. Например для 8 OLTP и 2 DSS нам потребуется 10 машин из тех, что имеют по 6 дополнительных дисков.
С двух терминалов сразу
1. # fio --client oltp.list fio-oltp.cfg
2. # fio --client dss.list fio-dss.cfg
Казалось бы, все идет хорошо. Каждая система показывает себя неплохо, и ничего не предвещает беды. Сделаем беду сами!
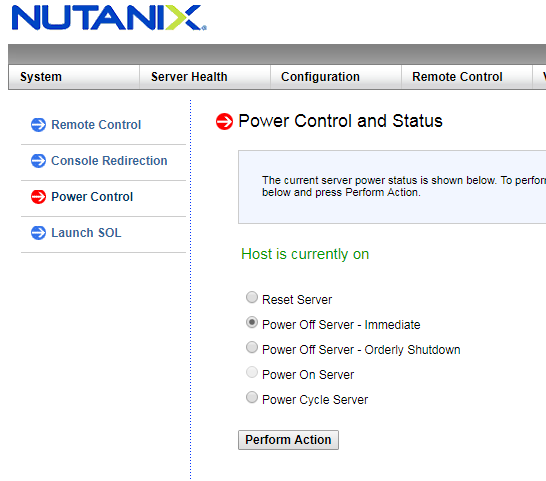
Теперь наблюдаем как под нагрузкой система будет перестраиваться и как это изменит показатели. Особое внимание обратите на "умные" системы, которые откладывают перестроение и восстановление отказоустойчивости на час и более. Не, ну а что такого? А вдруг это ничего страшного нет, подумаешь узел вылетел. Зато на тестах красивые цифры останутся. Если не читать то, что мелким шрифтом в глубинах документации.
Nutanix начинает процесс восстановления автоматически, через 30 секунд после недоступности CVM. Даже если это легитимная операция как например перезагрузка при обновлении.
При помощи подобного нехитрого руководства можно попробовать - а подходит ли вам предлагаемая вендором / интегратором система.
Ну или конечно, вы можете просто скачать Nutanix XRay, которая сделает все это в автоматическом режиме с красивыми графиками для платформ Nutanix AHV и VMware! :)



Комментариев нет:
Отправить комментарий