В vSphere есть отличная функция Storage IO Control, которая используется для предотвращения захвата всей пропускной способности одной виртуальной машиной или хостом. Для определения момента захвата ресурсов одним источником SIOC мониторит задержки работы СХД, и после определённого порога урезает глубину очереди к массиву.
Вопрос в том, какие именно метрики задержек отслеживаются SIOC - среднее время ответа устройства (DAVG), время ответа ядра (KAVG) или задержки ВМ (GAVG)?
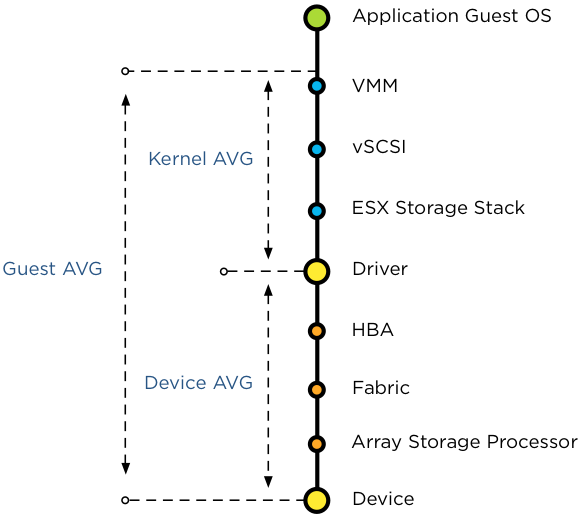
Вопрос в том, какие именно метрики задержек отслеживаются SIOC - среднее время ответа устройства (DAVG), время ответа ядра (KAVG) или задержки ВМ (GAVG)?
На самом деле ни одна из них. Все они являются локальными метриками планировщика ресурсов, которые и отвечает за отправку всех запросов к СХД. Основная же задача SIOC - управлять ресурсами общей СХД между несколькими ESXi хостами, предоставляя IO ресурсы для всех ВМ независимо от того на каком хосте они работают. И так как SIOC должен регулировать и приоритезировать доступ к общему хранилищу нескольких ESXi хостов, локальные метрики хоста игнорируются. Но какие же, в таком случае, используются метрики? По сути, пороговое значение сравнивается со средним значением DAVG на каждом хосте и средним количеством IOPS на хосте.


